I just wrote about The Hypocrisy of the Web . In order to check what others think about this issue I posted the following question to Yahoo Answers: is adding fresh content to your site hypocrisy?
In a few minutes I got very interesting answers:
1. Here's the answer that johnwaynenoblepi gave:
Yes and No. Some users are actually getting paid for the traffic that goes to there website as a promotion for some other product. That is thier livelyhood. On the other hand thier are mischiefious individuals out thier with no education that have nothing better to do than to use someone elses program to entice website visitors into clicking on something in their website that has destructive consequences. What comes around, goes around.
John
A+ Certified Professional
2. Here's the answer that serf gave:
Why would it be hypocricy? That doesn't make any sense.
3. Here's the answer that Mmmdlite gave:
People have a right to post whatever ever they want on their personal space. It's not hypocracy to try to generate traffic. This is the same reason why corporations have TV commercials...it's not hypocrytical, it's a way to gain business.
And let's take a look at the definition of hypocrisy:
1. The practice of professing beliefs, feelings, or virtues that one does not hold or possess; falseness.
2. An act or instance of such falseness.
Unless what they are posting goes against what they believe, how could it be hypocricy?
4. Here's the answer that hazel_nut333 gave:
Hypocrisy is if a person advocates Anti-New Contents and went about and add new contents to their site. That's the definition of hypocrisy.
You, for some reason, think people should only add contents to their sites if and only if it for the sole purpose of sharing knowledge.
What a closed minded and idiotiotic way to portray the Internet. IT'S THE FREAKING INTERNET!!!
5. Here's the answer that Jane Furrows gave:
Hypocrisy isn't the right word. As long as they have permission to use those articles, it's okay, especially if they have other articles there that people would be interested in and would help people find what they are looking for. The sites that annoy me are those that just mirror Wikipedia content but with tons of ads all over the place. I always make sure to go straight to the source for those.
I want to thank each of these kind answerers.
I think using Yahoo Answers for such a survey is fun and a very good way to learn something new.
BTW – This is a nice and easy way to add fresh content to your site.
Tuesday, January 31, 2006
Monday, January 30, 2006
Better Yahoo Answers
After I wrote about the need to improve Google answers I checked the first results in Yahoo for the query words "yahoo Answers" and made a comparison between these search results and the new QTsearch-Ranking-Version results.
QTsearch-Ranking-Version picked up the best and most extensive answer out of 5, while on Yahoo the 2 top results out of 1,030,000 were more narrow and restricted and only the third result was satisfactory (the same that QTsearch picked up).
I thought this comparison was quite amazing since Yahoo is the owner of Yahoo Answers and one could expect that the first or second results will be the best.
I think because the current search engines are retrieving so many results (1,030,000 in this case) they are not built to tailor better answers for thier users needs and there is room for QTsearch algorithm to be implemented on any such search engine in order to give users the best answers from the first results-pages that are retrieved.
Following is the comparison itself:
QTsearch best result:
The Birth of Yahoo Answers: http://blog.searchenginewatch.com/blog/051207-220118
Now out in beta is Yahoo Answers, Yahoo's new social networking/online community/question answering service. The service allows any registered Yahoo user to ask just about any question and hopefully get an answer from another member of the question answering community. Access to Yahoo Answers is free.
Yahoo Answers appears to be definite extension of what Yahoo's Senior Vice President, Search and Marketplace, Jeff Weiner, calls FUSE (Find, Use, Share, Expand) and Yahoo's numerous efforts into online community building with services like Web 2.0.
At the moment Yahoo Answers offers 23 top-level categories like:
Yahoo Answers uses a point and level system to reward participants:
Looking at the Yahoo Answers point system, it appears to me that there is an incentive to answer as many questions as possible as quickly as possible without worrying about accuracy.I think that's going to need some tuning.
Yahoo Results 1 - 5 of about 1,030,000
1 Yahoo! Answers
a place where people ask each other questions on any topic, and get answers by sharing facts, opinions, and personal experiences.
answers.yahoo.com
2. Yahoo! (Nasdaq: YHOO)
Yahoo! Internet portal provides email, news, shopping, web search, music, fantasy sports, and many other online products and services to consumers and businesses worldwide.
yahoo.com
3. The Birth of Yahoo Answers
You are in the: ClickZ Network ... Now out in beta is Yahoo Answers, Yahoo's new social networking/online community/question answering service ... Access to Yahoo Answers is free. Yahoo Answers appears to be definite ...
blog.searchenginewatch.com/blog/051207-220118
QTsearch-Ranking-Version picked up the best and most extensive answer out of 5, while on Yahoo the 2 top results out of 1,030,000 were more narrow and restricted and only the third result was satisfactory (the same that QTsearch picked up).
I thought this comparison was quite amazing since Yahoo is the owner of Yahoo Answers and one could expect that the first or second results will be the best.
I think because the current search engines are retrieving so many results (1,030,000 in this case) they are not built to tailor better answers for thier users needs and there is room for QTsearch algorithm to be implemented on any such search engine in order to give users the best answers from the first results-pages that are retrieved.
Following is the comparison itself:
QTsearch best result:
The Birth of Yahoo Answers: http://blog.searchenginewatch.com/blog/051207-220118
Now out in beta is Yahoo Answers, Yahoo's new social networking/online community/question answering service. The service allows any registered Yahoo user to ask just about any question and hopefully get an answer from another member of the question answering community. Access to Yahoo Answers is free.
Yahoo Answers appears to be definite extension of what Yahoo's Senior Vice President, Search and Marketplace, Jeff Weiner, calls FUSE (Find, Use, Share, Expand) and Yahoo's numerous efforts into online community building with services like Web 2.0.
At the moment Yahoo Answers offers 23 top-level categories like:
Yahoo Answers uses a point and level system to reward participants:
Looking at the Yahoo Answers point system, it appears to me that there is an incentive to answer as many questions as possible as quickly as possible without worrying about accuracy.I think that's going to need some tuning.
Yahoo Results 1 - 5 of about 1,030,000
1 Yahoo! Answers
a place where people ask each other questions on any topic, and get answers by sharing facts, opinions, and personal experiences.
answers.yahoo.com
2. Yahoo! (Nasdaq: YHOO)
Yahoo! Internet portal provides email, news, shopping, web search, music, fantasy sports, and many other online products and services to consumers and businesses worldwide.
yahoo.com
3. The Birth of Yahoo Answers
You are in the: ClickZ Network ... Now out in beta is Yahoo Answers, Yahoo's new social networking/online community/question answering service ... Access to Yahoo Answers is free. Yahoo Answers appears to be definite ...
blog.searchenginewatch.com/blog/051207-220118
Sunday, January 29, 2006
Looking for Love
The expression "Looking for Love" is a homonym - an expression with multiple meanings.
When you're looking for love in the real world you expect to find one
match between your soul and one other soul.
When you're looking for love in the virtual world you expect to find a lot of matches between the word 'love' in your query and the word 'love' in the results.
I hope that one day there will be no such division between the real and the virtual worlds and search engines will give users only one answer – the one that matches their needs!
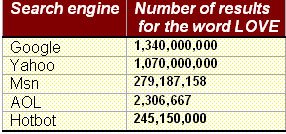
The same goes for the expression "Looking for God"

When you're looking for love in the real world you expect to find one
match between your soul and one other soul.
When you're looking for love in the virtual world you expect to find a lot of matches between the word 'love' in your query and the word 'love' in the results.
I hope that one day there will be no such division between the real and the virtual worlds and search engines will give users only one answer – the one that matches their needs!
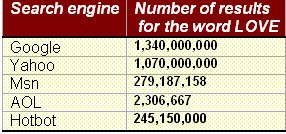
The same goes for the expression "Looking for God"

Saturday, January 28, 2006
Yahoo Answers
I just signed up to Yahoo Answers Beta and posted the following question:
Did Yahoo Answers Beta take the idea "to get answers from real people" from Wondir
(http://www. wondir. com/)?
Then I collected some excerpts with QTsearch in order to understand what Yahoo Answers is all about; and then I checked whether other people commented about the relationship between Yahoo Answers and Wondir .
What is Yahoo Answers all about?
The Birth of Yahoo Answers
http://blog. searchenginewatch. com/blog/051207-220118
Now out in beta is Yahoo Answers, Yahoo's new social networking/online community/question answering service. The service allows any registered Yahoo user to ask just about any question and hopefully get an answer from another member of the question answering community. Access to Yahoo Answers is free.
Yahoo Answers appears to be definite extension of what Yahoo's Senior Vice President, Search and Marketplace, Jeff Weiner, calls FUSE (Find, Use, Share, Expand) and Yahoo's numerous efforts into online community building with services like Web 2. 0.
At the moment Yahoo Answers offers 23 top-level categories like:
Yahoo Answers uses a point and level system to reward participants:
Looking at the Yahoo Answers point system, it appears to me that there is an incentive to answer as many questions as possible as quickly as possible without worrying about accuracy. I think that's going to need some tuning.
Both a simple search box and some advanced features are available for asked and answered questions. Yahoo Answers will be promoted on Yahoo Web Results pages. For example, a user might see a link to seek an answer to their info need on Yahoo Answers.
Yahoo! Search blog: Asking the Internet
http://www. ysearchblog. com/archives/000221. html
Sean O'Hagan made an interesting proposal. To spice up Yahoo Answers a little, more specific categories might be of great advantage for users to join and help each other!
I believe Yahoo! will prove itself in the coming times with Yahoo Answers
ResearchBuzz: Yahoo Launches Yahoo Answers
http://www. researchbuzz. org/2006/01/yahoo_launches_yahoo_answers. shtml
I drilled down the category listing to Science & Math / Zoology. Yahoo Answers divides the questions into unanswered (the most recently-asked questions are listed first) and answered.
Smart Mobs: Yahoo Answers:
http://www. smartmobs. com/archive/2006/01/11/yahoo_answers. html
Luke Biewald sent me some commentary on the new Yahoo Answers service launched in December:
You have to see these to believe them. So what is the problem with Yahoo Answers? The implementation seems to be working very hard to reduce questions like this. While they have built in a point system, it doesn't seem to have an effect in bubbling up good questions or answers.
Listed below are links to weblogs that reference Yahoo Answers:
Just caught this on Smart Mobs, an answer from Luke Biewald (really a Yahoo employee?) about the Yahoo Answers service:"This idea is really obvious, but has the potential to be as transformative as the Wikipedia.
What do people say about Yahoo answers and Wondir?
IP Democracy
http://www. ipdemocracy. com/archives/2005/12/08/index. php
Turns out Revolution Health Group is controlled by Steve Case, whose assortment of recent investments are reviewed in this IPD post. When Revolution’s acquisition of Wondir was announced a few months ago, it was presented as one of multiple investments closely tied the healthcare industry. But the launch of Yahoo Answers (and Price’s post), serves as a reminder that Wondir has broader capabilities and potential applications. It makes one wonder if Case has bigger plans for Wondir.
Yahoo! Answers Relies on the Kindness—and Knowledgeability—of. . . : http://www. infotoday. com/newsbreaks/nb051219-1. shtml
Other companies in the answer business have also moved in this direction. Answers. com recently acquired a search engine technology company called Brainboost that uses natural language processing to outline and analyze search results for context. In May, I reported on another collaborative answer service called Wondir, developed by information industry stalwart Matt Koll (“Wondir Launches Volunteer Virtual Reference Service,” http://www. infotoday. com/newsbreaks/nb050502-1. shtml
).
Mayer indicated that Yahoo! had spoken with Koll and looked at Wondir but ultimately decided that the number of users Yahoo!Answers would draw from the mammoth Yahoo! userbase would make it more successful than Wondir.
Hello World: Yahoo Answers
http://yanivg. blogspot. com/2005/12/yahoo-answers. html
Yahoo Answers is not the first attempt at this. In fact, Susan Mernit referred to it as a YAAN - Yet Another Answer Network, comparing it to Wondir and to others. While it's true that Yahoo Answers is not much different then Wondir, which has been around for quite some time, the user experience in the Yahoo implementation is considerably more slick, and is likely to get better and better. Not to mention the fact that, not really surprisingly, Yahoo Answer got on its first day traffic similar to what Wondir is seeing after ~3 years of operation.
Like Wondir, Yahoo Answers suffers from the "initial impression" effect (we call this "The Harry Potter Effect" - whenever a new Harry Potter book is released, Wondir is swamped with Potter-related questions. . . ) - when a user enters the system and is exposed to the "most recent" questions list, the content of these questions determines the flavor of the service in the eyes of the user. And given the random nature of this most recent list, and the topics which people are most interested at, that initial impression may cause users who are valuable knowledge sources to click-back-away. Again, if leveraging the long tail of knowledge is a goal of the service, thought should be given to this topic as well.
TechCrunch " Yahoo Answers Launches
http://www. techcrunch. com/2005/12/08/yahoo-answers-launches
My understanding is that the service will be somewhat similar to Yahoo Answers, Wondir, Google Answers and Oyogi, with some key differences that the founders hope will result in significantly more user participation, and better answers.
Did Yahoo Answers Beta take the idea "to get answers from real people" from Wondir
(http://www. wondir. com/)?
Then I collected some excerpts with QTsearch in order to understand what Yahoo Answers is all about; and then I checked whether other people commented about the relationship between Yahoo Answers and Wondir .
What is Yahoo Answers all about?
The Birth of Yahoo Answers
http://blog. searchenginewatch. com/blog/051207-220118
Now out in beta is Yahoo Answers, Yahoo's new social networking/online community/question answering service. The service allows any registered Yahoo user to ask just about any question and hopefully get an answer from another member of the question answering community. Access to Yahoo Answers is free.
Yahoo Answers appears to be definite extension of what Yahoo's Senior Vice President, Search and Marketplace, Jeff Weiner, calls FUSE (Find, Use, Share, Expand) and Yahoo's numerous efforts into online community building with services like Web 2. 0.
At the moment Yahoo Answers offers 23 top-level categories like:
Yahoo Answers uses a point and level system to reward participants:
Looking at the Yahoo Answers point system, it appears to me that there is an incentive to answer as many questions as possible as quickly as possible without worrying about accuracy. I think that's going to need some tuning.
Both a simple search box and some advanced features are available for asked and answered questions. Yahoo Answers will be promoted on Yahoo Web Results pages. For example, a user might see a link to seek an answer to their info need on Yahoo Answers.
Yahoo! Search blog: Asking the Internet
http://www. ysearchblog. com/archives/000221. html
Sean O'Hagan made an interesting proposal. To spice up Yahoo Answers a little, more specific categories might be of great advantage for users to join and help each other!
I believe Yahoo! will prove itself in the coming times with Yahoo Answers
ResearchBuzz: Yahoo Launches Yahoo Answers
http://www. researchbuzz. org/2006/01/yahoo_launches_yahoo_answers. shtml
I drilled down the category listing to Science & Math / Zoology. Yahoo Answers divides the questions into unanswered (the most recently-asked questions are listed first) and answered.
Smart Mobs: Yahoo Answers:
http://www. smartmobs. com/archive/2006/01/11/yahoo_answers. html
Luke Biewald sent me some commentary on the new Yahoo Answers service launched in December:
You have to see these to believe them. So what is the problem with Yahoo Answers? The implementation seems to be working very hard to reduce questions like this. While they have built in a point system, it doesn't seem to have an effect in bubbling up good questions or answers.
Listed below are links to weblogs that reference Yahoo Answers:
Just caught this on Smart Mobs, an answer from Luke Biewald (really a Yahoo employee?) about the Yahoo Answers service:"This idea is really obvious, but has the potential to be as transformative as the Wikipedia.
What do people say about Yahoo answers and Wondir?
IP Democracy
http://www. ipdemocracy. com/archives/2005/12/08/index. php
Turns out Revolution Health Group is controlled by Steve Case, whose assortment of recent investments are reviewed in this IPD post. When Revolution’s acquisition of Wondir was announced a few months ago, it was presented as one of multiple investments closely tied the healthcare industry. But the launch of Yahoo Answers (and Price’s post), serves as a reminder that Wondir has broader capabilities and potential applications. It makes one wonder if Case has bigger plans for Wondir.
Yahoo! Answers Relies on the Kindness—and Knowledgeability—of. . . : http://www. infotoday. com/newsbreaks/nb051219-1. shtml
Other companies in the answer business have also moved in this direction. Answers. com recently acquired a search engine technology company called Brainboost that uses natural language processing to outline and analyze search results for context. In May, I reported on another collaborative answer service called Wondir, developed by information industry stalwart Matt Koll (“Wondir Launches Volunteer Virtual Reference Service,” http://www. infotoday. com/newsbreaks/nb050502-1. shtml
).
Mayer indicated that Yahoo! had spoken with Koll and looked at Wondir but ultimately decided that the number of users Yahoo!Answers would draw from the mammoth Yahoo! userbase would make it more successful than Wondir.
Hello World: Yahoo Answers
http://yanivg. blogspot. com/2005/12/yahoo-answers. html
Yahoo Answers is not the first attempt at this. In fact, Susan Mernit referred to it as a YAAN - Yet Another Answer Network, comparing it to Wondir and to others. While it's true that Yahoo Answers is not much different then Wondir, which has been around for quite some time, the user experience in the Yahoo implementation is considerably more slick, and is likely to get better and better. Not to mention the fact that, not really surprisingly, Yahoo Answer got on its first day traffic similar to what Wondir is seeing after ~3 years of operation.
Like Wondir, Yahoo Answers suffers from the "initial impression" effect (we call this "The Harry Potter Effect" - whenever a new Harry Potter book is released, Wondir is swamped with Potter-related questions. . . ) - when a user enters the system and is exposed to the "most recent" questions list, the content of these questions determines the flavor of the service in the eyes of the user. And given the random nature of this most recent list, and the topics which people are most interested at, that initial impression may cause users who are valuable knowledge sources to click-back-away. Again, if leveraging the long tail of knowledge is a goal of the service, thought should be given to this topic as well.
TechCrunch " Yahoo Answers Launches
http://www. techcrunch. com/2005/12/08/yahoo-answers-launches
My understanding is that the service will be somewhat similar to Yahoo Answers, Wondir, Google Answers and Oyogi, with some key differences that the founders hope will result in significantly more user participation, and better answers.
Friday, January 27, 2006
The Hypocrisy of the Web
Roger Landry writes on his Blog about "Ranking in Google the Secret's Out". This is one of the best examples I ever saw for the habits people are forced to adopt in order to survive: millions of Web users are writing not in order to express themselves or truly share information with others but in order to add fresh content to their sites so that there will be enough traffic of visitors to buy whatever they are selling. The macro picture is quite amazing – the Web is getting full with hypocrisy!
I'm not saying that hypocrisy is bad, or that survival is bad –on the contrary, all this shows how vital is the game called competition!
I'm not saying that hypocrisy is bad, or that survival is bad –on the contrary, all this shows how vital is the game called competition!
Thursday, January 26, 2006
Better Answers
Google is so successful that we don't expect it to get better, but there is always room for improvement.
Today I looked for the words "Table of Contents" on QTsearch and got 3 answers – the first was exceptionally good because it described what a "Table of Contents" is and the others were good enough because they brought an example of a "Table of Contents". In Google I got 230,000,000 results and the top 10 were good enough examples of a "Table of Contents". I thought that if search engines will see to it that the first answer for any query will be an answer to the question "what is this" users will feel much more satisfied than in the current situation, in which they get confused by the many examples and don't get the overall picture.
So here are the sources for this recommendation: (you can repeat this little experiment and see for yourselves):
QTsearch:
http://en.wikipedia.org/wiki?title=Table_of_contents
A table of contents is an organized list of titles for quick information on the summary of a book or document and quickly directing the reader to any topic.Usually, printed tables of contents indicate page numbers where each section starts, while online ones offer links to go to each section. In English works the table of contents is at the beginning of a book; in French it is at the back, by the index.
Table of contents for the Pachypodium genus : http://en.wikipedia.org/wiki?title=Table_of_contents_for_the_Pachypodium_genus
Table of Contents for the Pachypodium Genus
Infotrieve Online : http://www.infotrieve.com/journals/toc_main.asp
Table of Contents (TOC) is a database providing the display of tables of contents of journals.The TOC alert service delivers tables of contents to you as they arrive from the publisher based on journal titles you've pre-selected and entered into your TOC profile. Only titles marked with the icon are available for alert and delivery.
Google:
Web Style Guide, 2nd Edition - 12:22am
... by Design book cover Buy Sarah Horton's new book, Access by Design, at Amazon.com • Web site hosted by Pair.com • Print table of contents. Jump to top ...
www.webstyleguide.com/ - 20k - 21 Jan 2006 - Cached - Similar pages - Remove result
Abridged Table of Contents
Abridged Table of Contents ... How to Cite • Editorial Information • About the SEP • Unabridged Table of Contents • Advanced Search • Advanced Tools ...
plato.stanford.edu/contents.html - 101k - Cached - Similar pages - Remove result
Smithsonian Institution
Composed of sixteen museums and galleries, the National Zoo, and numerous research facilities in the United States and abroad.
www.si.edu/ - 59k - 21 Jan 2006 - Cached - Similar pages - Remove result
Today I looked for the words "Table of Contents" on QTsearch and got 3 answers – the first was exceptionally good because it described what a "Table of Contents" is and the others were good enough because they brought an example of a "Table of Contents". In Google I got 230,000,000 results and the top 10 were good enough examples of a "Table of Contents". I thought that if search engines will see to it that the first answer for any query will be an answer to the question "what is this" users will feel much more satisfied than in the current situation, in which they get confused by the many examples and don't get the overall picture.
So here are the sources for this recommendation: (you can repeat this little experiment and see for yourselves):
QTsearch:
http://en.wikipedia.org/wiki?title=Table_of_contents
A table of contents is an organized list of titles for quick information on the summary of a book or document and quickly directing the reader to any topic.Usually, printed tables of contents indicate page numbers where each section starts, while online ones offer links to go to each section. In English works the table of contents is at the beginning of a book; in French it is at the back, by the index.
Table of contents for the Pachypodium genus : http://en.wikipedia.org/wiki?title=Table_of_contents_for_the_Pachypodium_genus
Table of Contents for the Pachypodium Genus
Infotrieve Online : http://www.infotrieve.com/journals/toc_main.asp
Table of Contents (TOC) is a database providing the display of tables of contents of journals.The TOC alert service delivers tables of contents to you as they arrive from the publisher based on journal titles you've pre-selected and entered into your TOC profile. Only titles marked with the icon are available for alert and delivery.
Google:
Web Style Guide, 2nd Edition - 12:22am
... by Design book cover Buy Sarah Horton's new book, Access by Design, at Amazon.com • Web site hosted by Pair.com • Print table of contents. Jump to top ...
www.webstyleguide.com/ - 20k - 21 Jan 2006 - Cached - Similar pages - Remove result
Abridged Table of Contents
Abridged Table of Contents ... How to Cite • Editorial Information • About the SEP • Unabridged Table of Contents • Advanced Search • Advanced Tools ...
plato.stanford.edu/contents.html - 101k - Cached - Similar pages - Remove result
Smithsonian Institution
Composed of sixteen museums and galleries, the National Zoo, and numerous research facilities in the United States and abroad.
www.si.edu/ - 59k - 21 Jan 2006 - Cached - Similar pages - Remove result
Tuesday, January 24, 2006
QTsearch
QTsearch has some features that are different from other current search engines. Some of these features can be utilized by these other search engines in order to help users navigate and find what they need.
1. Micro contents - current search engines supply macro contents which give users more than they can chew, while QTsearch produces relevant micro contents.
2. One results page – QTsearch provides the results themselves on one page instead of providing links to the results and snippets to describe them.
3. Few manageable results – and not daunting numbers like 100000 results and more.
4. No advertisements.
5. Meta search – QTsearch extracts chunks from multiple sources so that users can get answers even if one of the sources doesn't have it.
6. Snippets - Current search engines have old fashioned snippets that confuse users and let them guess what's in the link. QTsearch can make clear transparent snippets (from their first results pages) that help users navigate.
7. Suggestions - Some current search engines don't have suggestions to refine queries while QTsearch users can add the suggestions to their new queries in order to refine them.
8. Best answers - QTsearch algorithm can be implemented on any current search engine and give users the best answers from the first results-pages that are retrieved.
9. Accessibility - current search engines have severe accessibility problems while QTsearch can manipulate their results so that those who have difficulties in reading will hear the information with Opera browser.
10. Mobile - QTsearch can make current search engine results fit to Mobile devices.
11. Sorting – QTsearch lets users process the results on-line so that they can filter manually all the superfluous information and get the cleanest possible answers.
1. Micro contents - current search engines supply macro contents which give users more than they can chew, while QTsearch produces relevant micro contents.
2. One results page – QTsearch provides the results themselves on one page instead of providing links to the results and snippets to describe them.
3. Few manageable results – and not daunting numbers like 100000 results and more.
4. No advertisements.
5. Meta search – QTsearch extracts chunks from multiple sources so that users can get answers even if one of the sources doesn't have it.
6. Snippets - Current search engines have old fashioned snippets that confuse users and let them guess what's in the link. QTsearch can make clear transparent snippets (from their first results pages) that help users navigate.
7. Suggestions - Some current search engines don't have suggestions to refine queries while QTsearch users can add the suggestions to their new queries in order to refine them.
8. Best answers - QTsearch algorithm can be implemented on any current search engine and give users the best answers from the first results-pages that are retrieved.
9. Accessibility - current search engines have severe accessibility problems while QTsearch can manipulate their results so that those who have difficulties in reading will hear the information with Opera browser.
10. Mobile - QTsearch can make current search engine results fit to Mobile devices.
11. Sorting – QTsearch lets users process the results on-line so that they can filter manually all the superfluous information and get the cleanest possible answers.
Monday, January 23, 2006
Google Competitors
Not so long ago, on December 21, 2005, I wrote about the European and the Japanese Google competitors – and now I read on the news about another such group that the Norwegians are organizing. As I already noted I believe no group will succeed to beat Google on its own MACRO-CONTENT game field. Only a group that will develop a new MICRO-CONTENT search engine will have a chance to build a meaninful machine.
Here are some excerpts about these new competitors:
http://www.pandia.com/sew/162-europan-search-engine-alliance-to-challenge-google.html
According to the Norwegian policy newletter Mandag Morgen (Monday Morning) Fast and Schibsted are now building an research alliance with Accenture and several universities in Norway, Ireland and the US, including the Norwegian University of Science and Technology (which gave birth to Fast), the University of Tromsø, the University of Oslo, the Norwegian School of Management, Dublin City University, University College Dublin and Cornell University in the US.
The partners are to invest some NOK 340 million (US$ 51 million) in the new research center Information Access Disruptions (iAd) over an eight year period, Monday Morning reports.
http://www.pandia.com/sew/107-fast-is-back-on-the-web-search-engine-scene.html
One of the reasons for this Norwegian search engine bonanza is that Google has expressed a special interest in this Internet savvy market. These companies would like to present localized search engines for the Norwegian Internet users before google.no becomes something more than a Norwegian language clone of google.com.
http://www.ketupa.net/schibsted.htm - Schibsted group: Overview
The Norwegian Schibsted group is a newspaper and book publisher with online and film interests, competing with Egmont, Sanoma WSOY, Metro and Bonnier.
Schibsted owns Aftenposten, the largest newspaper in Norway, 49.9% of Sweden's leading paper, Aftonbladet and all of Postimees, Estonia's largest daily.The group includes Norwegian tabloid Verdens Gang and papers in Spain and Estonia.
http://en.wikipedia.org/wiki/Schibsted - Schibsted - Wikipedia, the free encyclopedia
Schibsted is one of the leading media groups in Scandinavia.Schibsteds present activities relate to media products and rights in the field of newspapers, television, film, publishing, multimedia and mobile services. Schibsted has ownership in a variety of formats; paper, the Internet, television, cinema, video, DVD and wireless terminals (mobile telephones, PDAs etc.).Schibsteds headquarters are in Oslo. Most of the groups operations are based in Norway and Sweden, but the group has operations in 11 European countries; Spain, France and Switzerland among others.
http://www.ineedhits.com/free-tools/blog/2005/10/australian-scandianvian-partnership.aspx
- ineedhits SEM Blog: Australian-Scandianvian Partnership Takes on ...
Australian directory business Sensis has announced a joint venture agreement with Norwegian search technology company Fast Search & Transfer and Scandinavian media firm Schibsted to market Internet search and advertising capabilities throughout Europe. Sensis used Fast's search technology on its Australian search site sensis.com.au, which had over 1 million unique users in September...The joint venture will aim to sell its capabilities to directories and media company who want to create a search engine of their own which contains both proprietary local content and relevant web results. Sensis and Schibsted themselves are the joint venture's first customers, with others in the pipeline. However, since the big boys of search, especially Google and Yahoo!, are also heavily investing in local search, the joint venture will most likely face stiff competition. The new joint venture aims to employ 50 staff members by the end of the year, even though Sensis has announced that it will lay off up to 250 staff in Australia as part of a strategic realignment. The joint venture's headquarters will be located in London.
Here are some excerpts about these new competitors:
http://www.pandia.com/sew/162-europan-search-engine-alliance-to-challenge-google.html
According to the Norwegian policy newletter Mandag Morgen (Monday Morning) Fast and Schibsted are now building an research alliance with Accenture and several universities in Norway, Ireland and the US, including the Norwegian University of Science and Technology (which gave birth to Fast), the University of Tromsø, the University of Oslo, the Norwegian School of Management, Dublin City University, University College Dublin and Cornell University in the US.
The partners are to invest some NOK 340 million (US$ 51 million) in the new research center Information Access Disruptions (iAd) over an eight year period, Monday Morning reports.
http://www.pandia.com/sew/107-fast-is-back-on-the-web-search-engine-scene.html
One of the reasons for this Norwegian search engine bonanza is that Google has expressed a special interest in this Internet savvy market. These companies would like to present localized search engines for the Norwegian Internet users before google.no becomes something more than a Norwegian language clone of google.com.
http://www.ketupa.net/schibsted.htm - Schibsted group: Overview
The Norwegian Schibsted group is a newspaper and book publisher with online and film interests, competing with Egmont, Sanoma WSOY, Metro and Bonnier.
Schibsted owns Aftenposten, the largest newspaper in Norway, 49.9% of Sweden's leading paper, Aftonbladet and all of Postimees, Estonia's largest daily.The group includes Norwegian tabloid Verdens Gang and papers in Spain and Estonia.
http://en.wikipedia.org/wiki/Schibsted - Schibsted - Wikipedia, the free encyclopedia
Schibsted is one of the leading media groups in Scandinavia.Schibsteds present activities relate to media products and rights in the field of newspapers, television, film, publishing, multimedia and mobile services. Schibsted has ownership in a variety of formats; paper, the Internet, television, cinema, video, DVD and wireless terminals (mobile telephones, PDAs etc.).Schibsteds headquarters are in Oslo. Most of the groups operations are based in Norway and Sweden, but the group has operations in 11 European countries; Spain, France and Switzerland among others.
http://www.ineedhits.com/free-tools/blog/2005/10/australian-scandianvian-partnership.aspx
- ineedhits SEM Blog: Australian-Scandianvian Partnership Takes on ...
Australian directory business Sensis has announced a joint venture agreement with Norwegian search technology company Fast Search & Transfer and Scandinavian media firm Schibsted to market Internet search and advertising capabilities throughout Europe. Sensis used Fast's search technology on its Australian search site sensis.com.au, which had over 1 million unique users in September...The joint venture will aim to sell its capabilities to directories and media company who want to create a search engine of their own which contains both proprietary local content and relevant web results. Sensis and Schibsted themselves are the joint venture's first customers, with others in the pipeline. However, since the big boys of search, especially Google and Yahoo!, are also heavily investing in local search, the joint venture will most likely face stiff competition. The new joint venture aims to employ 50 staff members by the end of the year, even though Sensis has announced that it will lay off up to 250 staff in Australia as part of a strategic realignment. The joint venture's headquarters will be located in London.
Sunday, January 22, 2006
False Positives
1. Spider
Today I searched on Google for the words "spider identification" and got a site with identification of brown spiders .
I meant to search for "search engine spider identification" but I was so sure that "spider" is a computer program that I forgot the fact that this word is a homonym, a word that has multiple meanings. It quite amused me and I thought it would be nice to collect false positives on this web page and to update the page whenever I find new ones. Readers are invited to add False Positives on their comments form.
2. Home
On Wikipedia I found a False Positive right in the definition of the term "False Positive".
3. Pray and 'Bare feet'
Beware of homonyms:
4. Apple
If you enter the word "apple" into Google search looking for the tree or the fruit of that tree you'll have to scan a few hundred results about the company by that name before you find what you asked for.
5. organization and color
Aside from cultural differences there are spelling differences as well. American spellings vary from English; you might be missing your answer by only searching organisation (organization) and color (colour).
6. Polish/polish
Homonyms
7. Police
If you type in police, you get a lot of pages about the rock group.
8. Football
Free text
9. Cobra
10. China
11. Cook
http://www.sciam.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21&pageNumber=5&catID=2
An intelligent search program can sift through all the pages of people whose name is "Cook" (sidestepping all the pages relating to cooks, cooking, the Cook Islands and so forth),
12. cat/cats
http://en.wikipedia.org/wiki/Folksonomy
Today I searched on Google for the words "spider identification" and got a site with identification of brown spiders .
I meant to search for "search engine spider identification" but I was so sure that "spider" is a computer program that I forgot the fact that this word is a homonym, a word that has multiple meanings. It quite amused me and I thought it would be nice to collect false positives on this web page and to update the page whenever I find new ones. Readers are invited to add False Positives on their comments form.
2. Home
On Wikipedia I found a False Positive right in the definition of the term "False Positive".
In computer database searching, false positives are documents that are retrieved by a search despite their irrelevance to the search question. False positives are common in full text searching, in which the search algorithm examines all of the text in all of the stored documents in an attempt to match one or more search terms supplied by the user.
Most false positives can be attributed to the deficiencies of natural language, which is often ambiguous: the term "home," for example, may mean "a person's dwelling" or "the main or top-level page in a Web site." The false positive rate can be reduced by using a controlled vocabulary, but this solution is expensive because the vocabulary must be developed by an expert and applied to documents by trained indexers.
3. Pray and 'Bare feet'
Beware of homonyms:
Two words are homonyms if they are pronounced or spelled the same way but have different meanings. A good example is 'pray' and 'prey'. If you look up information on a 'praying mantis', you'll find facts about a religious insect rather than one that seeks out and eats others. 'Bare feet' and 'bear feet' are two very different things! If you use the wrong word to describe your search you will find interesting, but wrong, results.
4. Apple
If you enter the word "apple" into Google search looking for the tree or the fruit of that tree you'll have to scan a few hundred results about the company by that name before you find what you asked for.
5. organization and color
Aside from cultural differences there are spelling differences as well. American spellings vary from English; you might be missing your answer by only searching organisation (organization) and color (colour).
6. Polish/polish
Homonyms
can affect your search: China/china or Polish/polish.
7. Police
If you type in police, you get a lot of pages about the rock group.
8. Football
Free text
searching is likely to retrieve many documents that are not relevant to the search question. Such documents are called false positives. The retrieval of irrelevant documents is often caused by the inherent ambiguity of natural language; for example, in the United States, football refers to what is called American football outside the U.S.; throughout the rest of the world, football refers to what Americans call soccer. A search for football may retrieve documents that are about two completely different sports.
9. Cobra
href="http://www.sims.berkeley.edu/courses/is141/f05/lectures/jpedersen.pdf">Jan Pedersen, Chief Scientist, Yahoo! Search wrote on 19 September 2005 about The Four Dimensions of Search Engine Quality and in the chapter about Handling Ambiguity
brought nine pictures of different things called "cobra" (snake, car, helicopter etc.)
10. China
Quickly finding documents is indeed easy. Finding relevant documents, however, is a challenge that information retrieval (IR) researchers have been addressing for more than 40 years. The numerous ambiguities inherent in natural language make this search problem incredibly difficult. For example, a query about "China" can refer to either a country or dinnerware.
11. Cook
http://www.sciam.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21&pageNumber=5&catID=2
An intelligent search program can sift through all the pages of people whose name is "Cook" (sidestepping all the pages relating to cooks, cooking, the Cook Islands and so forth),
12. cat/cats
http://en.wikipedia.org/wiki/Folksonomy
Phenomena that may cause problems include polysemy, words which have multiple related meanings (a window can be a hole or a sheet of glass); synonym, multiple words with the same or similar meanings (tv and television, or Netherlands/Holland/Dutch) and plural words (cat and cats)
Friday, January 20, 2006
Search Engine Spider Identification
On my Site Meter I get mysterious numbers like 64. 233. 173. 85 or like 193. 47. 80.
Theoretically I knew that spiders visit my Blog but I never knew how to trace them. Today I saw an excellent guide by John A Fotheringham with a list of Spider Identifications. I tried to search there for 64.233.173.85 and other such numbers and got no match. Suddenly I had this bright idea to Google "64.233.173.85" and voila – I got it on Search Engine Spider Identification And it’s the Google Spider!
Then I saw on my Site Meter that the spiders' name (Google) is on the ISP field.
So I got some confidence and tried to trace the 193.47.80 spider and voila – on the ISP field I saw that it's Exalead, about which I just posted
Theoretically I knew that spiders visit my Blog but I never knew how to trace them. Today I saw an excellent guide by John A Fotheringham with a list of Spider Identifications. I tried to search there for 64.233.173.85 and other such numbers and got no match. Suddenly I had this bright idea to Google "64.233.173.85" and voila – I got it on Search Engine Spider Identification And it’s the Google Spider!
Then I saw on my Site Meter that the spiders' name (Google) is on the ISP field.
So I got some confidence and tried to trace the 193.47.80 spider and voila – on the ISP field I saw that it's Exalead, about which I just posted
Thursday, January 19, 2006
Exalead
Exalead is a France-based company that is involved in the President Jacques Chirac's initiative to develop Quaero , a European substitute for Google.
From my point of view Exalead is another macro content search engine with old fashioned snippets and I don't see where they take their confidence from when they try to compete with Google which is the best in this macro content field.
Only micro content strategy will help them change the basic rules of the game.
I liked Exalead's wonderful feature of "related terms" that takes you directly to the webpages you need.
I think it’s a big step towards one answer machine.
Here are some excerpts I collected in order to get acquainted with Exalead:
http://www.pandia.com/sew/149-the-multimedia-search-engine-quaero-europe%E2%80%99s-answer-to-google.html
Several companies are involved in the Quaero project along with Thompson. AFP’s article mentions Deutsche Telecom, France Telecom, and the search engine Exalead. This is very promising – Exalead has an interface that makes Google look out of date.
http://www.seroundtable.com/archives/001385.html
January 13, 2005
Exalead Searching 1,031,065,733 Web Pages
A while back, Google surpassed the 8 billion mark, and Gigablast Broke 1k the other day. John Battellle reported; Exalead, a company that powers AOL France's search (I was introduced to its founder by Alta Vista founder Louis Monier - yup, he's French) announced today that its stand alone search engine has surpassed the 1-billion-pages-indexed mark. (The engine launched in October)." Louis Monier was on the panel at SES on the search memories session, you can see his picture there, smart, visionary and funny guy.
Gary Price reports that Exalead's Paris-based CEO, Francois Bourdoncle, said "that the company plans to have a two billion page web index online in the near future. He also said that his company is about just ready to introduce a desktop search tool."
http://www.searchenginejournal.com/index.php?p=1752
Although Exalead’s results are not as relevant as the top search engines, Exalead is doing some interesting things on the presentation side.
Exalead allows users to filter by related search terms, related categories (clustering), web site location (local search), and document type. Users can also restrict results to websites containing links to audio or video content.
All results have a thumbnail of the homepage.
But thats not all Exalead is experimenting with. Clicking on a result loads up the page in a bottom frame with the search terms highlighted on the page. This allows for quick scanning and a fast way to determine if the result is relevant to the initial search. If the page isn’t relevant, users have instant access to the search results.
http://enterprise.amd.com/downloadables/Exalead_ISS_20050713a.pdf
In 2004, the Paris, France-based company wanted to showcase a new international searching service on powerful enterprise-class technology, in the quest to become the No. 1 information-access leader.
Although Exalead started business in 2000, its roots in search engine technology run deeper. Exalead's founders developed the company's dynamic categorization technology while working at the Ecoles des Mines de Paris, one of the top engineering schools in France. Exalead CEO François Bourdoncle and board member Louis Monier were early developers of the AltaVista search engine, and they wanted to build a similar vehicle for the Web.
2. http://searchenginewatch. com/searchday/article. php/3507266 Introducing a New Web Search Contender
These days, web search is dominated by giants, and it's rare to see the emergence of a new potentially world-class search engine. Meet Exalead, a powerful search tool with features not offered by the major search engines.
Exalead is a fairly new search engine from France, introduced in October 2004 and still officially in beta. Having passed the one-billion page mark in 2005, it's still 1/8th the size of Google or Yahoo, but what's a few billion pages among friends? Actually, after a certain point, size really doesn't matter.
The key factors in evaluating a search engine should include timeliness, ability to handle ambiguity, and plenty of power search tools. Exalead does a great job, at least on two of these three criteria.
Exalead is one of the only search engines to allow proximity searching(!), in which the words you search must be within 16 words of each other. (No, you can't tweak the number of intervening words. )
Exalead also lets you use "Regular Expressions," in which you can search for documents with words that match a certain pattern. Imagine, for example, that you're doing a crossword puzzle and have a word of 6 letters, of which the second is T and the sixth is C. By searching /. t. . . c/, you will retrieve sites with the word ATOMIC, perhaps the right word for your puzzle.
3. http://www. pandia. com/sew/110-interesting-exalead-upgrade. html » Interesting Exalead upgrade
The French search engine Exalead has been given fair credit for its advanced search functions, including truncation, proximity search, stemming, phonetic search, language field search. There has now been an interesting upgrade.
Since December 2004 there has been an option letting you add your own links under the search field on the search engine’s home page, giving you the opportunity to turn the Exalead home page into your own portal. Now you may add up till 18 shortcuts of this kind. Hence you may add links to other search engines, making it possible to do your search using other search engines by clicking on the thumbnail appearing under the search form.
4. http://www. erexchange. com/BLOGS/CyberSleuthing?LISTINGID=AFA82E22391841F1B820D26BEB43A351 CyberSleuthing!: Exalead goes full circle | ERE Blog Network
This includes sponsored links by Espotting, and also Exalead Web technology that uses statistical analysis to compare the search terms with the content found in Web pages. When searching for say, "Natacha, hotesse de l'air", the name of a comic strip by Walthיry about an air stewardess, Exalead takes you straight to the site of the artist, grifil. net. The same search with Google gives results overrun with extraneous content.
Exalead the company has been around for 4 years, and the "beta" search was announced so why the sudden news coverage? There is little note worthy news stories about Exalead prior to May 20th of this year.
From my point of view Exalead is another macro content search engine with old fashioned snippets and I don't see where they take their confidence from when they try to compete with Google which is the best in this macro content field.
Only micro content strategy will help them change the basic rules of the game.
I liked Exalead's wonderful feature of "related terms" that takes you directly to the webpages you need.
I think it’s a big step towards one answer machine.
Here are some excerpts I collected in order to get acquainted with Exalead:
http://www.pandia.com/sew/149-the-multimedia-search-engine-quaero-europe%E2%80%99s-answer-to-google.html
Several companies are involved in the Quaero project along with Thompson. AFP’s article mentions Deutsche Telecom, France Telecom, and the search engine Exalead. This is very promising – Exalead has an interface that makes Google look out of date.
http://www.seroundtable.com/archives/001385.html
January 13, 2005
Exalead Searching 1,031,065,733 Web Pages
A while back, Google surpassed the 8 billion mark, and Gigablast Broke 1k the other day. John Battellle reported; Exalead, a company that powers AOL France's search (I was introduced to its founder by Alta Vista founder Louis Monier - yup, he's French) announced today that its stand alone search engine has surpassed the 1-billion-pages-indexed mark. (The engine launched in October)." Louis Monier was on the panel at SES on the search memories session, you can see his picture there, smart, visionary and funny guy.
Gary Price reports that Exalead's Paris-based CEO, Francois Bourdoncle, said "that the company plans to have a two billion page web index online in the near future. He also said that his company is about just ready to introduce a desktop search tool."
http://www.searchenginejournal.com/index.php?p=1752
Although Exalead’s results are not as relevant as the top search engines, Exalead is doing some interesting things on the presentation side.
Exalead allows users to filter by related search terms, related categories (clustering), web site location (local search), and document type. Users can also restrict results to websites containing links to audio or video content.
All results have a thumbnail of the homepage.
But thats not all Exalead is experimenting with. Clicking on a result loads up the page in a bottom frame with the search terms highlighted on the page. This allows for quick scanning and a fast way to determine if the result is relevant to the initial search. If the page isn’t relevant, users have instant access to the search results.
http://enterprise.amd.com/downloadables/Exalead_ISS_20050713a.pdf
In 2004, the Paris, France-based company wanted to showcase a new international searching service on powerful enterprise-class technology, in the quest to become the No. 1 information-access leader.
Although Exalead started business in 2000, its roots in search engine technology run deeper. Exalead's founders developed the company's dynamic categorization technology while working at the Ecoles des Mines de Paris, one of the top engineering schools in France. Exalead CEO François Bourdoncle and board member Louis Monier were early developers of the AltaVista search engine, and they wanted to build a similar vehicle for the Web.
2. http://searchenginewatch. com/searchday/article. php/3507266 Introducing a New Web Search Contender
These days, web search is dominated by giants, and it's rare to see the emergence of a new potentially world-class search engine. Meet Exalead, a powerful search tool with features not offered by the major search engines.
Exalead is a fairly new search engine from France, introduced in October 2004 and still officially in beta. Having passed the one-billion page mark in 2005, it's still 1/8th the size of Google or Yahoo, but what's a few billion pages among friends? Actually, after a certain point, size really doesn't matter.
The key factors in evaluating a search engine should include timeliness, ability to handle ambiguity, and plenty of power search tools. Exalead does a great job, at least on two of these three criteria.
Exalead is one of the only search engines to allow proximity searching(!), in which the words you search must be within 16 words of each other. (No, you can't tweak the number of intervening words. )
Exalead also lets you use "Regular Expressions," in which you can search for documents with words that match a certain pattern. Imagine, for example, that you're doing a crossword puzzle and have a word of 6 letters, of which the second is T and the sixth is C. By searching /. t. . . c/, you will retrieve sites with the word ATOMIC, perhaps the right word for your puzzle.
3. http://www. pandia. com/sew/110-interesting-exalead-upgrade. html » Interesting Exalead upgrade
The French search engine Exalead has been given fair credit for its advanced search functions, including truncation, proximity search, stemming, phonetic search, language field search. There has now been an interesting upgrade.
Since December 2004 there has been an option letting you add your own links under the search field on the search engine’s home page, giving you the opportunity to turn the Exalead home page into your own portal. Now you may add up till 18 shortcuts of this kind. Hence you may add links to other search engines, making it possible to do your search using other search engines by clicking on the thumbnail appearing under the search form.
4. http://www. erexchange. com/BLOGS/CyberSleuthing?LISTINGID=AFA82E22391841F1B820D26BEB43A351 CyberSleuthing!: Exalead goes full circle | ERE Blog Network
This includes sponsored links by Espotting, and also Exalead Web technology that uses statistical analysis to compare the search terms with the content found in Web pages. When searching for say, "Natacha, hotesse de l'air", the name of a comic strip by Walthיry about an air stewardess, Exalead takes you straight to the site of the artist, grifil. net. The same search with Google gives results overrun with extraneous content.
Exalead the company has been around for 4 years, and the "beta" search was announced so why the sudden news coverage? There is little note worthy news stories about Exalead prior to May 20th of this year.
Wednesday, January 18, 2006
Cow9
An infobroker who reviewed QT/Search told me that the suggestions for further search are similar to Cow9. A quick search on QT/Search for the word Cow9 taught me that this feature disappeared from Alta Vista. I'm not a journalist so I didn't dig into this story, but I feel it in my bones that there is something juicy to discover here about the reasons why such a wonderful feature disappeared just like that. Another interesting angle to explore is how the writer who wrote a whole guide to Cow9 feels when he sees the empty space that replaced the cow9 refine button.
So here's what I collected about cow9:
1. http://www. samizdat. com/script/lt1. htm AltaVista's LiveTopics, AKA Refine, code-named Cow9
Cow9 is a powerful feature that was once offered through AltaVista, first under the name LiveTopics, later called Refine. The project, code named "Cow9," was a collaborative effort between researchers at Digital Equipment Corporation and François Bourdoncle of Ecole des Mines de Paris, www. ensmp. fr The underlying technology has enormous potential. To get a sense for how it can be used, check these slides and the screen-capture examples. (FYI -- the screen captures were made in October 1997).
2. http://www.wadsworth. com/english_d/templates/resources/0838408265_harbrace/research/research12.html Student Resources
Use the "Cow9" function to refine, or narrow, your search by selecting the "Refine" button located to the right of the query field. By doing so, the "Refine's List View" will display the results in the order of relevance so that you can require or exclude topics using a drop-down menu.
3. http://tsc.k12.in.us/training/SEARCH/ALTAVIST/HELP.HTM
LiveTopics is a tool that helps you refine and analyze the results of an AltaVista search.
LiveTopics analyzes the contents of documents that meet your original search criteria and displays groups of additional words, called topics, to use in refining your query. Topics are dynamically generated from words that occur frequently in the documents that match your initial search criteria. Topics appear in order of relevance, and words inside a topic are ordered by frequency of occurrence.
This dynamic generation of related topics, tailored to each search, distinguishes LiveTopics from other web search aids, which offer predetermined categories or structures into which you must fit your query.
The LiveTopics technology was developed for AltaVista by Francois Bourdoncle of the Ecole des Mines de Paris/ARMINES.
4. http://www. buffalo.edu/reporter/vol28/vol28n23/eh.html
Mar. 6, 1997-Vol28n23: Electronic Highways: LiveTopics from AltaVista
AltaVista now offers LiveTopics to assist you in refining the results of your initial search. This new tool offers related terms or topics, generated from your initial search for you to select, or exclude, to help you narrow your search. The terms are produced by frequency in which the word appears in the set of documents.
Choosing LiveTopics offers terms such as qualifications, racial, candidates, tenure, hiring, diversity, women, and recruitment. In addition you may choose subcategories such as salary, position, experience, and minorities. You may then choose to include or omit certain terms from your initial search, reducing the number of documents originally found.
LiveTopics is most useful when you receive more than 200 documents in your initial search. Anything smaller usually results in irrelevant related terms.
5. http://www.ariadne.ac.uk/issue9/search-engines
If you perform a search for 'Ariadne' on Alta Vista you retrieve around 9000 documents. None of our first 10 hits appear to be relevant to our search for the journal as they are links to software companies of the same name. With a set of results of this size, Alta Vista automatically prompts you to refine your search using LiveTopics.LiveTopics brings up a number of topic headings - including mythology, Amiga, Goddess, OPACS, UKOLN and Libraries. We can now exclude all of the irrelevant documents from our search by clicking on the irrelevant subjects to place a cross in the boxes next to them.
This brings my search results down from 9000 documents to around 200. I can then go back and further refine my search if necessary.Alta Vista prompts me to use LiveTopics to summarise my results: if I choose this option it will re-define the categories of topics in my search results and present me with a new set of options based on these dynamic categories.
6. http://www.faculty.de.gcsu.edu/~hpowers/search/altavist.htm
Alta Vista's REFINE feature provides an online thesaurus based on the terms in each of your search results.The terms it offers are based on a statistical analysis of the frequency of appearance of words in the Web pages your search retrieved (they are not drawn from some standardized thesaurus or Websters). They are ranked with most frequent first.
You can modify your search by excluding or adding terms from the groups offered by the thesaurus .
So here's what I collected about cow9:
1. http://www. samizdat. com/script/lt1. htm AltaVista's LiveTopics, AKA Refine, code-named Cow9
Cow9 is a powerful feature that was once offered through AltaVista, first under the name LiveTopics, later called Refine. The project, code named "Cow9," was a collaborative effort between researchers at Digital Equipment Corporation and François Bourdoncle of Ecole des Mines de Paris, www. ensmp. fr The underlying technology has enormous potential. To get a sense for how it can be used, check these slides and the screen-capture examples. (FYI -- the screen captures were made in October 1997).
2. http://www.wadsworth. com/english_d/templates/resources/0838408265_harbrace/research/research12.html Student Resources
Use the "Cow9" function to refine, or narrow, your search by selecting the "Refine" button located to the right of the query field. By doing so, the "Refine's List View" will display the results in the order of relevance so that you can require or exclude topics using a drop-down menu.
3. http://tsc.k12.in.us/training/SEARCH/ALTAVIST/HELP.HTM
LiveTopics is a tool that helps you refine and analyze the results of an AltaVista search.
LiveTopics analyzes the contents of documents that meet your original search criteria and displays groups of additional words, called topics, to use in refining your query. Topics are dynamically generated from words that occur frequently in the documents that match your initial search criteria. Topics appear in order of relevance, and words inside a topic are ordered by frequency of occurrence.
This dynamic generation of related topics, tailored to each search, distinguishes LiveTopics from other web search aids, which offer predetermined categories or structures into which you must fit your query.
The LiveTopics technology was developed for AltaVista by Francois Bourdoncle of the Ecole des Mines de Paris/ARMINES.
4. http://www. buffalo.edu/reporter/vol28/vol28n23/eh.html
Mar. 6, 1997-Vol28n23: Electronic Highways: LiveTopics from AltaVista
AltaVista now offers LiveTopics to assist you in refining the results of your initial search. This new tool offers related terms or topics, generated from your initial search for you to select, or exclude, to help you narrow your search. The terms are produced by frequency in which the word appears in the set of documents.
Choosing LiveTopics offers terms such as qualifications, racial, candidates, tenure, hiring, diversity, women, and recruitment. In addition you may choose subcategories such as salary, position, experience, and minorities. You may then choose to include or omit certain terms from your initial search, reducing the number of documents originally found.
LiveTopics is most useful when you receive more than 200 documents in your initial search. Anything smaller usually results in irrelevant related terms.
5. http://www.ariadne.ac.uk/issue9/search-engines
If you perform a search for 'Ariadne' on Alta Vista you retrieve around 9000 documents. None of our first 10 hits appear to be relevant to our search for the journal as they are links to software companies of the same name. With a set of results of this size, Alta Vista automatically prompts you to refine your search using LiveTopics.LiveTopics brings up a number of topic headings - including mythology, Amiga, Goddess, OPACS, UKOLN and Libraries. We can now exclude all of the irrelevant documents from our search by clicking on the irrelevant subjects to place a cross in the boxes next to them.
This brings my search results down from 9000 documents to around 200. I can then go back and further refine my search if necessary.Alta Vista prompts me to use LiveTopics to summarise my results: if I choose this option it will re-define the categories of topics in my search results and present me with a new set of options based on these dynamic categories.
6. http://www.faculty.de.gcsu.edu/~hpowers/search/altavist.htm
Alta Vista's REFINE feature provides an online thesaurus based on the terms in each of your search results.The terms it offers are based on a statistical analysis of the frequency of appearance of words in the Web pages your search retrieved (they are not drawn from some standardized thesaurus or Websters). They are ranked with most frequent first.
You can modify your search by excluding or adding terms from the groups offered by the thesaurus .
Tuesday, January 17, 2006
World Brain
1. about 70 years ago H.G. Wells in his book World Brain (1938)
In those days nobody could have taken him seriously but the late advancements in search engines technology raise afresh the question of the feasibility of this vision.
2. Fifty years ago Eugene Garfield invented "citation analysis" (1955) as a step in the fulfillment of H.G. Wells' World Brain vision and commented (1981) that
3. Five years ago Google founders, Sergey Brin and Lawrence Page, wrote a paper about the need to make Google. They cited Garfield's work . It seems that Google (with other search engines) is another step in the fulfillment of this vision. Eric Magnuson ,for example, gave one of his Blog postings the following title: Google creating the world brain.
4. Nowadays the Web 2.0 microcontent revolution seems to be another step in the fulfillment of this World Brain vision. Gooogle users get macro-content pages (very quickly) with much more information than they need. Microcontent search engines are going to supply the exact amount of needed information and to organize it much more efficiently. H.G. Wells vision was to build a good world brain, not a jabberer.
envisioned a 'World Encyclopedia' in which multidisciplinary research information of a global nature would be gathered together and made available for the immediate use of anyone in the world.
In those days nobody could have taken him seriously but the late advancements in search engines technology raise afresh the question of the feasibility of this vision.
2. Fifty years ago Eugene Garfield invented "citation analysis" (1955) as a step in the fulfillment of H.G. Wells' World Brain vision and commented (1981) that
computer technology of our own day is beginning to make such a concept feasible.
3. Five years ago Google founders, Sergey Brin and Lawrence Page, wrote a paper about the need to make Google. They cited Garfield's work . It seems that Google (with other search engines) is another step in the fulfillment of this vision. Eric Magnuson ,for example, gave one of his Blog postings the following title: Google creating the world brain.
4. Nowadays the Web 2.0 microcontent revolution seems to be another step in the fulfillment of this World Brain vision. Gooogle users get macro-content pages (very quickly) with much more information than they need. Microcontent search engines are going to supply the exact amount of needed information and to organize it much more efficiently. H.G. Wells vision was to build a good world brain, not a jabberer.
Monday, January 16, 2006
PageRank
Today I stumbled upon Prase, a new Page Ranking search engine, and started experimenting with it. Soon I discovered that I need to know the basics of Page Ranking in order to understand how to make the most out of it - so I entered the word PageRank into QT/Search to collect some chunks:
About Prase
http://www. hawaiistreets. com/seoblog/seoblog. php?itemid=547
Prase stands for PageRank Assisted Search Engine. As of today, I think Prase could be the best link-building tool there is. First of all, it's free and second of all, it lacks the spammy downloads other companies offer you. I've been playing around with Prase for a few minutes this morning and am already taken in by features it has to offer.
1. Search multiple databases by keywords Prase gives you the ability to select from Google and/or Yahoo! and/or MSN as database providers. Simply enter a keyword you associate with a perfect link partner and Prase will return you the results.
2. Sort by PageRank Before you begin a search, you have an option of choosing a PageRank range. This is especially useful if you are trying to either gain backlinks from a high PR site or bypass those sites all together.
When you search, results are sorted for you from highest PR to the lowest.
Start the search anywhere you want You can tell Prase where to begin displaying search results. A useful feature again if you are trying to avoid top sites and target medium or lower end sites. Prase is going on to my del. icio. us list for great service and usability. As an SEO, I am very impressed with service it offers putting to shame companies that try to sell you similar software.
http://www. geekvillage. com/forums/showthread. php?s=e542a4abe1c1e7b25a40743f60c6373d&postid=163100#post163100
There have been other Page Rank search engines, but this one is a bit different in the way it does things.
This search engine would mainly be of interest to people who want to see sites listed according to PageRank. That would include people interested in exchanging links with sites based on their PageRank.
Great they have a higher PageRank, but you are higher in the search results. Since PRASE has results listed by Page Rank, the best site for the searched term isn't always shown at or near the top. That isn't to imply that what is always shown first in the search results is always the best when they aren't arrange by PageRank. With PRASE it is easy to see that the sites with the highest PageRank often aren't the ones that are first in the natural results. The results are sorted three times by PRASE First they are sorted by search engine. Then they are sorted according to PageRank. Then they are finalized by listing them in decending order based on their search engine ranking.
If there is a tie in search engine ranking, the listing is done based upon search engine market share with Google first, Yahoo second and then MSN. The main purpose of PRASE is to search based upon PageRank and to easily show that. It has an added feature that allows you to search for sites within a certain range. The default is between 0 and 9.
About PageRank
1. http://en. wikipedia. org/wiki/PageRank
PageRank, sometimes abbreviated to PR, is a family of algorithms for assigning numerical weightings to hyperlinked documents (or web pages) indexed by a search engine originally developed by Larry Page (thus the play on the words PageRank). Its properties are much discussed by search engine optimization (SEO) experts. The PageRank system is used by the popular search engine Google to help determine a page's relevance or importance. It was developed by Google's founders Larry Page and Sergey Brin while at Stanford University in 1998.
PageRank relies on the uniquely democratic nature of the web by using its vast link structure as an indicator of an individual page's value. Google interprets a link from page A to page B as a vote, by page A, for page B. But Google looks at more than the sheer volume of votes, or links a page receives; it also analyzes the page that casts the vote.
A hyperlink to a page counts as a vote of support. The PageRank of a page is defined recursively and depends on the number and PageRank metric of all pages that link to it ("incoming links"). A page that is linked by many pages with high rank receives a high rank itself. If there are no links to a web page there is no support of this specific page.
http://en.wikipedia.org/wiki/Google_search
Google uses an algorithm called PageRank to rank web pages that match a given search string. The PageRank algorithm computes a recursive figure of merit for web pages, based on the weighted sum of the PageRanks of the pages linking to them. The PageRank thus derives from human-generated links, and correlates well with human concepts of importance. Previous keyword-based methods of ranking search results, used by many search engines that were once more popular than Google, would rank pages by how often the search terms occurred in the page, or how strongly associated the search terms were within each resulting page. In addition to PageRank, Google also uses other secret criteria for determining the ranking of pages on result lists.
Search engine optimization encompasses both "on page" factors (like body copy, title tags, H1 heading tags and image alt attributes) and "off page" factors (like anchor text and PageRank). The general idea is to affect Google's relevance algorithm by incorporating the keywords being targeted in various places "on page," in particular the title tag and the body copy (note: the higher up in the page, the better its keyword prominence and thus the ranking). Too many occurrences of the keyword, however, cause the page to look suspect to Google's spam checking algorithms.
http://en.wikipedia.org/wiki/Search_engine
PageRank is based on citation analysis that was developed in the 1950s by Eugene Garfield at the University of Pennsylvania. Google's founders cite Garfield's work in their original paper. In this way virtual communities of webpages are found.
http://www-db.stanford.edu/~backrub/google.html
The Anatomy of a Large-Scale Hypertextual Web Search Engine
Sergey Brin and Lawrence Page
sergey, page}@cs.stanford.edu
Computer Science Department, Stanford University, Stanford, CA 94305
http://www.iprcom.com/papers/pagerank/
PageRank is also displayed on the toolbar of your browser if you’ve installed the Google toolbar (http://toolbar. google. com/).
PageRank says nothing about the content or size of a page, the language it’s written in, or the text used in the anchor of a link!
The PageRank displayed in the Google toolbar in your browser. This ranges from 0 to 10.
In short PageRank is a “vote”, by all the other pages on the Web, about how important a page is. A link to a page counts as a vote of support. If there’s no link there’s no support (but it’s an abstention from voting rather than a vote against the page).
About Prase
http://www. hawaiistreets. com/seoblog/seoblog. php?itemid=547
Prase stands for PageRank Assisted Search Engine. As of today, I think Prase could be the best link-building tool there is. First of all, it's free and second of all, it lacks the spammy downloads other companies offer you. I've been playing around with Prase for a few minutes this morning and am already taken in by features it has to offer.
1. Search multiple databases by keywords Prase gives you the ability to select from Google and/or Yahoo! and/or MSN as database providers. Simply enter a keyword you associate with a perfect link partner and Prase will return you the results.
2. Sort by PageRank Before you begin a search, you have an option of choosing a PageRank range. This is especially useful if you are trying to either gain backlinks from a high PR site or bypass those sites all together.
When you search, results are sorted for you from highest PR to the lowest.
Start the search anywhere you want You can tell Prase where to begin displaying search results. A useful feature again if you are trying to avoid top sites and target medium or lower end sites. Prase is going on to my del. icio. us list for great service and usability. As an SEO, I am very impressed with service it offers putting to shame companies that try to sell you similar software.
http://www. geekvillage. com/forums/showthread. php?s=e542a4abe1c1e7b25a40743f60c6373d&postid=163100#post163100
There have been other Page Rank search engines, but this one is a bit different in the way it does things.
This search engine would mainly be of interest to people who want to see sites listed according to PageRank. That would include people interested in exchanging links with sites based on their PageRank.
Great they have a higher PageRank, but you are higher in the search results. Since PRASE has results listed by Page Rank, the best site for the searched term isn't always shown at or near the top. That isn't to imply that what is always shown first in the search results is always the best when they aren't arrange by PageRank. With PRASE it is easy to see that the sites with the highest PageRank often aren't the ones that are first in the natural results. The results are sorted three times by PRASE First they are sorted by search engine. Then they are sorted according to PageRank. Then they are finalized by listing them in decending order based on their search engine ranking.
If there is a tie in search engine ranking, the listing is done based upon search engine market share with Google first, Yahoo second and then MSN. The main purpose of PRASE is to search based upon PageRank and to easily show that. It has an added feature that allows you to search for sites within a certain range. The default is between 0 and 9.
About PageRank
1. http://en. wikipedia. org/wiki/PageRank
PageRank, sometimes abbreviated to PR, is a family of algorithms for assigning numerical weightings to hyperlinked documents (or web pages) indexed by a search engine originally developed by Larry Page (thus the play on the words PageRank). Its properties are much discussed by search engine optimization (SEO) experts. The PageRank system is used by the popular search engine Google to help determine a page's relevance or importance. It was developed by Google's founders Larry Page and Sergey Brin while at Stanford University in 1998.
PageRank relies on the uniquely democratic nature of the web by using its vast link structure as an indicator of an individual page's value. Google interprets a link from page A to page B as a vote, by page A, for page B. But Google looks at more than the sheer volume of votes, or links a page receives; it also analyzes the page that casts the vote.
A hyperlink to a page counts as a vote of support. The PageRank of a page is defined recursively and depends on the number and PageRank metric of all pages that link to it ("incoming links"). A page that is linked by many pages with high rank receives a high rank itself. If there are no links to a web page there is no support of this specific page.
http://en.wikipedia.org/wiki/Google_search
Google uses an algorithm called PageRank to rank web pages that match a given search string. The PageRank algorithm computes a recursive figure of merit for web pages, based on the weighted sum of the PageRanks of the pages linking to them. The PageRank thus derives from human-generated links, and correlates well with human concepts of importance. Previous keyword-based methods of ranking search results, used by many search engines that were once more popular than Google, would rank pages by how often the search terms occurred in the page, or how strongly associated the search terms were within each resulting page. In addition to PageRank, Google also uses other secret criteria for determining the ranking of pages on result lists.
Search engine optimization encompasses both "on page" factors (like body copy, title tags, H1 heading tags and image alt attributes) and "off page" factors (like anchor text and PageRank). The general idea is to affect Google's relevance algorithm by incorporating the keywords being targeted in various places "on page," in particular the title tag and the body copy (note: the higher up in the page, the better its keyword prominence and thus the ranking). Too many occurrences of the keyword, however, cause the page to look suspect to Google's spam checking algorithms.
http://en.wikipedia.org/wiki/Search_engine
PageRank is based on citation analysis that was developed in the 1950s by Eugene Garfield at the University of Pennsylvania. Google's founders cite Garfield's work in their original paper. In this way virtual communities of webpages are found.
http://www-db.stanford.edu/~backrub/google.html
The Anatomy of a Large-Scale Hypertextual Web Search Engine
Sergey Brin and Lawrence Page
sergey, page}@cs.stanford.edu
Computer Science Department, Stanford University, Stanford, CA 94305
http://www.iprcom.com/papers/pagerank/
PageRank is also displayed on the toolbar of your browser if you’ve installed the Google toolbar (http://toolbar. google. com/).
PageRank says nothing about the content or size of a page, the language it’s written in, or the text used in the anchor of a link!
The PageRank displayed in the Google toolbar in your browser. This ranges from 0 to 10.
In short PageRank is a “vote”, by all the other pages on the Web, about how important a page is. A link to a page counts as a vote of support. If there’s no link there’s no support (but it’s an abstention from voting rather than a vote against the page).
Sunday, January 15, 2006
Web Cache
Currently web-Cache applications are storing MACRO-CONTENT query results. I assume that in the near future there will be storage of MICROCONTENT query results which will change dramatically the way people get their answers: Instead of getting many links to macro-content pages web-cache will retrieve one page with many relevant microcontent chunks.
In order to check the feasibility of this idea I asked QT/Saver to collect some information on the subject:
Contents:
To Increase Speed
Multiple Cache Servers
Little Used In North America
Cachelink
Cache-Friendly
Oracle Application Server
Site Dedicated To Caching
Book on Web Caching
Web Proxy
Reverse Proxy
Web Cache Copyright
To Increase Speed
Caching is a way to store requested Internet objects (e.g. data like web pages) available via the HTTP, FTP, and gopher protocols on a system closer to the requesting site. Web browsers can then use the local Squid cache as a proxy HTTP server, reducing access time as well as bandwidth consumption. This is often useful for Internet service providers to increase speed to their customers, and LANs that share an Internet connection. Because it is also a proxy (i.e. it behaves like a client on behalf of the real client), it provides some anonymity and security.
Suppose slow.example.com is a "real" web server, and www.example.com is a Squid cache server that "accelerates" it. The first time any page was requested from www.example.com, the cache server would get the actual page from slow.example.com, but for the next hour/day/year (matter of cache configuration) every next request would get this stored copy directly from the accelerator. The end result, without any action by the clients, is less traffic to the source server, meaning less CPU and memory usage, and less need for bandwidth.
Multiple Cache Servers
http://en.wikipedia.org/wiki/Web_cache Web cache - Wikipedia, the free encyclopedia
All major websites which routinely receive millions of queries per day require some form of web caching. If multiple cache servers are used together, these may coordinate using protocols like the Internet Cache Protocol and HTCP.
Little Used In North America
The Cache Now! campaign is designed to increase the awareness and use of proxy cache on the Web.
Web cache offers a win/win situation for both content providers and users, yet is little used in North America.
Cachelink
http://www.mangosoft.com/products/cachelink Mangosoft, Inc
Mangosoft's Cachelink software dramatically speeds access to commonly viewed web pages. Rather than going "outside" to the Internet to collect the information, Cachelink enables the information to be gathered "inside" within a local area network (LAN). This is achieved by storing web information within your local network - a technique known as "caching". Cachelink aggregates the cache from all of the PC's on a LAN and makes it available to the entire network.
Cache-Friendly
Caching Tutorial for Web Authors and Webmasters
The best way to make a script cache-friendly (as well as perform better) is to dump its content to a plain file whenever it changes. The Web server can then treat it like any other Web page, generating and using validators, which makes your life easier. Remember to only write files that have changed, so the Last-Modified times are preserved.
Oracle Application Server
OracleAS Web Cache
Oracle Application Server Web Cache 10g is the software industry's leading application acceleration solution…Built-in workload management features ensure application reliability and help maintain quality of service under heavy loads. And new in this release, end-user performance monitoring features provide unparalleled insight into end-user service levels.
http://www.oracle.com/technology/products/ias/htdocs/9iaswebcache_fov.html Oracle9ias Web Cache--Feature Overview--Oracle Corporation
ORACLE9iAS WEB CACHE Oracle9iAS Web Cache improves the scalability, performance and availability of e-business Web sites.
Web Cache combines caching, compression and assembly technologies to accelerate the delivery of both static and dynamically generated Web content. As the first application server to implement ESI, Oracle9i Application Server boasts the industry's fastest edge server, with support for partial-page caching, personalization and dynamic content assembly at the network edge. Oracle9iAS Web Cache also provides back-end Web server load balancing, failover and surge protection features which ensure blazing performance and rock-solid up-time.
Oracle9iAS Web Cache understands the contents of HTTP headers -- including cookies --and is capable of making caching and routing decisions based on administrator or application-defined cacheability rules. This "content awareness" makes it possible for administrators to cache different content for different categories of visitors, such as the ability to show full prices to new customers and discounted prices to returning customers.
Site Dedicated To Caching
Web Caching and Content Delivery Resources
Welcome to my web cache and content delivery network pages. This site is dedicated to providing a comprehensive guide to the resources about and in support of caching and content delivery on the World Wide Web. If you know of something that we are missing, make sure you tell us about it! This field, like many areas of the Web, is constantly changing so bookmark this site and come back often!
Book on Web Caching
Online Catalog: Web Caching, First Edition
A properly designed web cache, by reducing network traffic and improving access times to popular web sites, is a boon to network administrators and web users alike. This book hands you all the technical information you need to design, deploy, and operate an effective web caching service. It also covers the important political aspects of web caching, including privacy and security issues.
Web Proxy
A common proxy application is a caching Web proxy. This provides a nearby cache of Web pages and files available on remote Web servers, allowing local network clients to access them more quickly or reliably.
When it receives a request for a Web resource (specified by a URL), a caching proxy looks for the resulting URL in its local cache. If found, it returns the document immediately. Otherwise it fetches it from the remote server, returns it to the requester and saves a copy in the cache.
Google's Web Accelerator is an example of a split proxy.
Privoxy is a free, open source web proxy with privacy features
Sun Java System Web Proxy Server, formerly Sun ONE Web Proxy Server.
Reverse Proxy
A reverse proxy is a proxy server that is installed in the neighborhood of one or more servers..
There are several reasons for installing reverse proxy servers:
Encryption / SSL acceleration: when secure websites are created, the SSL encryption is sometimes not done by the webserver itself, but by a reverse proxy that is equiped with SSL acceleration hardware.
Load distribution: the reverse proxy can distribute the load to several servers, each server serving its own application area.
Caching static content: A reverse proxy can offload the webservers by caching static content, such as images. Proxy caching of this sort can often satisfy a considerable amount of website requests, greatly reducing the load on the central web server.
The Apache HTTP Server may be used as a reverse proxy.
Web Cache Copyright
Some people worry that web caching may be an act of copyright infringement. In 1998 the DMCA added rules to the United States Code (17 Sec. 512) that largely relieves system operators from copyright liability for the purposes of caching.
http://news.com.com/2100-1038_3-1024234.html Google cache raises copyright concerns | CNET News.com
As seemingly benign and beneficial as it is, some Web site operators take issue with the feature and digitally prevent Google from recording their pages in full by adding special code to their sites. Among other arguments, they say that cached pages at Google have the potential to detour traffic from their own site, or, at worst, constitute trademark or copyright violations. In the case of an out-of-date news page in Google's cache, a Web publisher could even face legal troubles because of false data remaining on the Web but corrected at its own site.
Admittedly, Google's cache is like any number of backdoors to information on the Web. For example, proxy servers can be the keys to a site that is banned by a visitor's hosting Web server. And technically, any time a Web surfer visits a site, that visit could be interpreted as a copyright violation, because the page is temporarily cached in the user's computer memory.
A provision in the Digital Millennium Copyright Act (DMCA) includes a safe harbor for Web caching. The safe harbor is narrowly defined to protect Internet service providers that cache Web pages to make them more readily accessible to subscribers. For example, AOL could keep a local copy of high-trafficked Web pages on its servers so that its members could access them with greater speed and less cost to the network. Various copyright lawyers argue that safe harbor may or may not protect Google if it was tested.
In order to check the feasibility of this idea I asked QT/Saver to collect some information on the subject:
Contents:
To Increase Speed
Multiple Cache Servers
Little Used In North America
Cachelink
Cache-Friendly
Oracle Application Server
Site Dedicated To Caching
Book on Web Caching
Web Proxy
Reverse Proxy
Web Cache Copyright
To Increase Speed
Caching is a way to store requested Internet objects (e.g. data like web pages) available via the HTTP, FTP, and gopher protocols on a system closer to the requesting site. Web browsers can then use the local Squid cache as a proxy HTTP server, reducing access time as well as bandwidth consumption. This is often useful for Internet service providers to increase speed to their customers, and LANs that share an Internet connection. Because it is also a proxy (i.e. it behaves like a client on behalf of the real client), it provides some anonymity and security.
Suppose slow.example.com is a "real" web server, and www.example.com is a Squid cache server that "accelerates" it. The first time any page was requested from www.example.com, the cache server would get the actual page from slow.example.com, but for the next hour/day/year (matter of cache configuration) every next request would get this stored copy directly from the accelerator. The end result, without any action by the clients, is less traffic to the source server, meaning less CPU and memory usage, and less need for bandwidth.
Multiple Cache Servers
http://en.wikipedia.org/wiki/Web_cache Web cache - Wikipedia, the free encyclopedia
All major websites which routinely receive millions of queries per day require some form of web caching. If multiple cache servers are used together, these may coordinate using protocols like the Internet Cache Protocol and HTCP.
Little Used In North America
The Cache Now! campaign is designed to increase the awareness and use of proxy cache on the Web.
Web cache offers a win/win situation for both content providers and users, yet is little used in North America.
Cachelink
http://www.mangosoft.com/products/cachelink Mangosoft, Inc
Mangosoft's Cachelink software dramatically speeds access to commonly viewed web pages. Rather than going "outside" to the Internet to collect the information, Cachelink enables the information to be gathered "inside" within a local area network (LAN). This is achieved by storing web information within your local network - a technique known as "caching". Cachelink aggregates the cache from all of the PC's on a LAN and makes it available to the entire network.
Cache-Friendly
Caching Tutorial for Web Authors and Webmasters
The best way to make a script cache-friendly (as well as perform better) is to dump its content to a plain file whenever it changes. The Web server can then treat it like any other Web page, generating and using validators, which makes your life easier. Remember to only write files that have changed, so the Last-Modified times are preserved.
Oracle Application Server
OracleAS Web Cache
Oracle Application Server Web Cache 10g is the software industry's leading application acceleration solution…Built-in workload management features ensure application reliability and help maintain quality of service under heavy loads. And new in this release, end-user performance monitoring features provide unparalleled insight into end-user service levels.
http://www.oracle.com/technology/products/ias/htdocs/9iaswebcache_fov.html Oracle9ias Web Cache--Feature Overview--Oracle Corporation
ORACLE9iAS WEB CACHE Oracle9iAS Web Cache improves the scalability, performance and availability of e-business Web sites.
Web Cache combines caching, compression and assembly technologies to accelerate the delivery of both static and dynamically generated Web content. As the first application server to implement ESI, Oracle9i Application Server boasts the industry's fastest edge server, with support for partial-page caching, personalization and dynamic content assembly at the network edge. Oracle9iAS Web Cache also provides back-end Web server load balancing, failover and surge protection features which ensure blazing performance and rock-solid up-time.
Oracle9iAS Web Cache understands the contents of HTTP headers -- including cookies --and is capable of making caching and routing decisions based on administrator or application-defined cacheability rules. This "content awareness" makes it possible for administrators to cache different content for different categories of visitors, such as the ability to show full prices to new customers and discounted prices to returning customers.
Site Dedicated To Caching
Web Caching and Content Delivery Resources
Welcome to my web cache and content delivery network pages. This site is dedicated to providing a comprehensive guide to the resources about and in support of caching and content delivery on the World Wide Web. If you know of something that we are missing, make sure you tell us about it! This field, like many areas of the Web, is constantly changing so bookmark this site and come back often!
Book on Web Caching
Online Catalog: Web Caching, First Edition
A properly designed web cache, by reducing network traffic and improving access times to popular web sites, is a boon to network administrators and web users alike. This book hands you all the technical information you need to design, deploy, and operate an effective web caching service. It also covers the important political aspects of web caching, including privacy and security issues.
Web Proxy
A common proxy application is a caching Web proxy. This provides a nearby cache of Web pages and files available on remote Web servers, allowing local network clients to access them more quickly or reliably.
When it receives a request for a Web resource (specified by a URL), a caching proxy looks for the resulting URL in its local cache. If found, it returns the document immediately. Otherwise it fetches it from the remote server, returns it to the requester and saves a copy in the cache.
Google's Web Accelerator is an example of a split proxy.
Privoxy is a free, open source web proxy with privacy features
Sun Java System Web Proxy Server, formerly Sun ONE Web Proxy Server.
Reverse Proxy
A reverse proxy is a proxy server that is installed in the neighborhood of one or more servers..
There are several reasons for installing reverse proxy servers:
Encryption / SSL acceleration: when secure websites are created, the SSL encryption is sometimes not done by the webserver itself, but by a reverse proxy that is equiped with SSL acceleration hardware.
Load distribution: the reverse proxy can distribute the load to several servers, each server serving its own application area.
Caching static content: A reverse proxy can offload the webservers by caching static content, such as images. Proxy caching of this sort can often satisfy a considerable amount of website requests, greatly reducing the load on the central web server.
The Apache HTTP Server may be used as a reverse proxy.
Web Cache Copyright
Some people worry that web caching may be an act of copyright infringement. In 1998 the DMCA added rules to the United States Code (17 Sec. 512) that largely relieves system operators from copyright liability for the purposes of caching.
http://news.com.com/2100-1038_3-1024234.html Google cache raises copyright concerns | CNET News.com
As seemingly benign and beneficial as it is, some Web site operators take issue with the feature and digitally prevent Google from recording their pages in full by adding special code to their sites. Among other arguments, they say that cached pages at Google have the potential to detour traffic from their own site, or, at worst, constitute trademark or copyright violations. In the case of an out-of-date news page in Google's cache, a Web publisher could even face legal troubles because of false data remaining on the Web but corrected at its own site.
Admittedly, Google's cache is like any number of backdoors to information on the Web. For example, proxy servers can be the keys to a site that is banned by a visitor's hosting Web server. And technically, any time a Web surfer visits a site, that visit could be interpreted as a copyright violation, because the page is temporarily cached in the user's computer memory.
A provision in the Digital Millennium Copyright Act (DMCA) includes a safe harbor for Web caching. The safe harbor is narrowly defined to protect Internet service providers that cache Web pages to make them more readily accessible to subscribers. For example, AOL could keep a local copy of high-trafficked Web pages on its servers so that its members could access them with greater speed and less cost to the network. Various copyright lawyers argue that safe harbor may or may not protect Google if it was tested.
Saturday, January 14, 2006
Co-Browsing
Three months ago I wrote about the need to have Group Browsing (also called Collaborative Browsing or Co-Browsing)and these says I found out that there's already software for this assignment. It seems that this software is having a lot of technical problems but anyhow it makes me happy to know that there are new possibilities to reduce illiteracy.
Background:
http://lieber. www. media. mit. edu/people/lieber/Lieberary/Lets-Browse/Lets-Browse. html
Web browsing, like most of today's desktop applications, is usually a solitary activity. Other forms of media, such as watching television, are often done by groups of people, such as families or friends. What would it be like to do collaborative Web browsing? Could the computer provide assistance to group browsing by trying to help find mutual interests among the participants?
Increasingly, Web browsing will be performed in collaborative settings, such as a family at home or in a business meeting. For example, WebTV estimates that the average number of people who are watching during a session with its service is two, indicating that multi-user browsing is the norm rather than the exception. In most such situations, one person has control of the remote or the keyboard and mouse, and the others present are relatively passive. Yet the browsing session can't be considered successful if the interests of others present are not taken into account.
Collaborative browsing (also known as co-browsing) is a software-enabled technique that allows someone in an enterprise contact center to interact with a customer by using the customer's Web browser to show them something. For example, a B2B customer having difficulty placing an order could call a customer service representative who could then show the customer how to use the ordering pages as though the customer were using their own mouse and keyboard. Collaborative browsing can include e-mail, fax, regular telephone, and Internet phone contact as part of an interaction. Effectively, collaborative browsing allows a company and a customer to "be on the same page. "
See a detailed description on how Co-Browsing works on
http://www.oregonlibraries.net/staff/?p=243
http://www.kolabora.com/news/2004/11/29/towards_a_new_generation_of.htm
Web touring (also known as co-browsing or collaborative browsing) is the ability to drive multiple participants to access a sequence of selected Web pages simultaneously.
For example, a customer having difficulty placing an order could call a customer service representative who could then enable co-browsing to see exactly what's on the customer's screen.
The must-have features of an ideal real-time Web conferencing system Web Touring and Co-Browsing facility include:
Pushing a Web page allows the presenter to force a specific Web page to appear on the end user screen…
Preview feature allows the presenter/moderator to literally pre-view a Web page before broadcasting it to all of the meeting participants.
The Hand-over control feature allows the presenter/moderator in a co-browsing session to give control of the Web tour to any one of the participants in the session.
The pre-caching feature allows the automatic and invisible pre-downloading of the Web pages to be viewed during a co-browsing session across all attendees.
Co-scrolling provides the ability to scroll Web pages simultaneously with all meeting participants. When the presenter scrolls a Web page, it simultaneously scrolls on all participants’ screens.
A shared pointing tool allows the presenter to show the mouse cursor to participants in real time over the Web page being shown.
New software:
http://www.masternewmedia.org/skype/co-browsing/co-browsing_and_call-forwarding_with_Jyve_20050720.htm
Co-browse web pages in synch with any Skype contact through a custom dedicated browser…By downloading a Skype plugin called Jyve…
http://www.downloadsquad.com/2005/08/23/googe-talk-review/
Google Talk…another big feature they're working on is "joint search," which would allow two or more Google Talk buddies using Google and surfing the web together. This would be a natural segue to the fabled Google Browser, but there is as yet no confirmation from Google.
http://educational.blogs.com/instructional_technology_/2005/01/collaborative_b.html
Advanced Reality Inc., a company specializing in peer-to-peer collaboration technology, has recently announced Jybe, a free beta release of a new browser based collaboration service.
http://www.mozillazine.org/talkback.html?article=5979
Jack Mott writes: "Our Company, Advanced Reality, recently released a new product as an open beta. Jybe is an extension for Firefox that allows you to link your browser together to one or more friends' browsers and allows you to chat and browse the web together. Initial features included full frames support, chat, and a powerpoint presentation system, with more to come. Additionally, our plugin for Firefox is cross compatible with our identical plugin for Internet Explorer.
http://www.tametheweb.com/ttwblog/archives/001266.html
So what's HOT about Jybe 2.0: An intuitive Create Session that features a Notify button so you can invite folks to your jybe session via email.
I am intrigued as usual by something that seems so simple to use that could make the VR folks sit up and take notice.
http://www.mozillazine.org/talkback.html?article=6632
Jack writes: "Jybe Beta2 has been released and addresses many of the suggestions we received from MozillaZine readers. Jybe allows Firefox and/or IE users to connect their browsers together. New features include collaborative text entry and scrolling, and Firefox users can now opt to hide the toolbar if they find it intrusive." We reported on the first Jybe beta in January.
http://google. weblogsinc. com/2005/08/24/googles-roar-sidebar-and-google-talk-in-one-week
Google is directing its community development toward group search or group browsing, and we all know what that leads to: The mythical Gbrowser. Everyone and their four-year-old kid has speculated on the possibility of a Google browser; this week's browser-like Sidebar certainly points in that direction.
http://citeseer. ist. psu. edu/555878. html
This paper presents a model of a system that enhances the current features of the Net by providing the users a facility to securely browse the Internet together. It thus provides the 'feeling of togetherness' on the Internet. The proposed system is generic and thus can be used to 'group enable' any existing and running site. It is a module that can be plugged onto existing systems without affecting their normal behavior. It would thus make concepts such as group shopping, group Medicare.
http://www.liveperson.com/sb/cobrowse.asp
With LivePerson's new Co-Browsing system, your Sales and Service Agents can assist your visitors in the completion of online forms and transactions. It has been designed to be fast, easy to use, and versatile.
Background:
http://lieber. www. media. mit. edu/people/lieber/Lieberary/Lets-Browse/Lets-Browse. html
Web browsing, like most of today's desktop applications, is usually a solitary activity. Other forms of media, such as watching television, are often done by groups of people, such as families or friends. What would it be like to do collaborative Web browsing? Could the computer provide assistance to group browsing by trying to help find mutual interests among the participants?
Increasingly, Web browsing will be performed in collaborative settings, such as a family at home or in a business meeting. For example, WebTV estimates that the average number of people who are watching during a session with its service is two, indicating that multi-user browsing is the norm rather than the exception. In most such situations, one person has control of the remote or the keyboard and mouse, and the others present are relatively passive. Yet the browsing session can't be considered successful if the interests of others present are not taken into account.
Collaborative browsing (also known as co-browsing) is a software-enabled technique that allows someone in an enterprise contact center to interact with a customer by using the customer's Web browser to show them something. For example, a B2B customer having difficulty placing an order could call a customer service representative who could then show the customer how to use the ordering pages as though the customer were using their own mouse and keyboard. Collaborative browsing can include e-mail, fax, regular telephone, and Internet phone contact as part of an interaction. Effectively, collaborative browsing allows a company and a customer to "be on the same page. "
See a detailed description on how Co-Browsing works on
http://www.oregonlibraries.net/staff/?p=243
http://www.kolabora.com/news/2004/11/29/towards_a_new_generation_of.htm
Web touring (also known as co-browsing or collaborative browsing) is the ability to drive multiple participants to access a sequence of selected Web pages simultaneously.
For example, a customer having difficulty placing an order could call a customer service representative who could then enable co-browsing to see exactly what's on the customer's screen.
The must-have features of an ideal real-time Web conferencing system Web Touring and Co-Browsing facility include:
Pushing a Web page allows the presenter to force a specific Web page to appear on the end user screen…
Preview feature allows the presenter/moderator to literally pre-view a Web page before broadcasting it to all of the meeting participants.
The Hand-over control feature allows the presenter/moderator in a co-browsing session to give control of the Web tour to any one of the participants in the session.
The pre-caching feature allows the automatic and invisible pre-downloading of the Web pages to be viewed during a co-browsing session across all attendees.
Co-scrolling provides the ability to scroll Web pages simultaneously with all meeting participants. When the presenter scrolls a Web page, it simultaneously scrolls on all participants’ screens.
A shared pointing tool allows the presenter to show the mouse cursor to participants in real time over the Web page being shown.
New software:
http://www.masternewmedia.org/skype/co-browsing/co-browsing_and_call-forwarding_with_Jyve_20050720.htm
Co-browse web pages in synch with any Skype contact through a custom dedicated browser…By downloading a Skype plugin called Jyve…
http://www.downloadsquad.com/2005/08/23/googe-talk-review/
Google Talk…another big feature they're working on is "joint search," which would allow two or more Google Talk buddies using Google and surfing the web together. This would be a natural segue to the fabled Google Browser, but there is as yet no confirmation from Google.
http://educational.blogs.com/instructional_technology_/2005/01/collaborative_b.html
Advanced Reality Inc., a company specializing in peer-to-peer collaboration technology, has recently announced Jybe, a free beta release of a new browser based collaboration service.
http://www.mozillazine.org/talkback.html?article=5979
Jack Mott writes: "Our Company, Advanced Reality, recently released a new product as an open beta. Jybe is an extension for Firefox that allows you to link your browser together to one or more friends' browsers and allows you to chat and browse the web together. Initial features included full frames support, chat, and a powerpoint presentation system, with more to come. Additionally, our plugin for Firefox is cross compatible with our identical plugin for Internet Explorer.
http://www.tametheweb.com/ttwblog/archives/001266.html
So what's HOT about Jybe 2.0: An intuitive Create Session that features a Notify button so you can invite folks to your jybe session via email.
I am intrigued as usual by something that seems so simple to use that could make the VR folks sit up and take notice.
http://www.mozillazine.org/talkback.html?article=6632
Jack writes: "Jybe Beta2 has been released and addresses many of the suggestions we received from MozillaZine readers. Jybe allows Firefox and/or IE users to connect their browsers together. New features include collaborative text entry and scrolling, and Firefox users can now opt to hide the toolbar if they find it intrusive." We reported on the first Jybe beta in January.
http://google. weblogsinc. com/2005/08/24/googles-roar-sidebar-and-google-talk-in-one-week
Google is directing its community development toward group search or group browsing, and we all know what that leads to: The mythical Gbrowser. Everyone and their four-year-old kid has speculated on the possibility of a Google browser; this week's browser-like Sidebar certainly points in that direction.
http://citeseer. ist. psu. edu/555878. html
This paper presents a model of a system that enhances the current features of the Net by providing the users a facility to securely browse the Internet together. It thus provides the 'feeling of togetherness' on the Internet. The proposed system is generic and thus can be used to 'group enable' any existing and running site. It is a module that can be plugged onto existing systems without affecting their normal behavior. It would thus make concepts such as group shopping, group Medicare.
http://www.liveperson.com/sb/cobrowse.asp
With LivePerson's new Co-Browsing system, your Sales and Service Agents can assist your visitors in the completion of online forms and transactions. It has been designed to be fast, easy to use, and versatile.
Friday, January 13, 2006
One Best Result
There's an interesting thread about the problem of getting ONE BEST RESULT from Google. I chose the most relevant excerpts, added titles and arranged them differently:
The Problem
Solutions:
Comments:
My Sum Up:
There are users who complain that search engines give them too many results.
(See also my posting about my-hall-of-frustration )
There are users who desire one right result.
There are users who think it is possible to create one right result, others think it's unrealistic.
I think we have to mark this as a target and ask ourselves how to get there.
I'm sure that QT/Search is a step in the right direction. since it retrieves only few results in which the search words appear in every chunk.
I'll try in the future to build a version that will choose the best answer from QT/Search SERP and give the user only one answer.
In case there is no such answer it will notify the user about it– that will also be only one answer – NO.
The Problem
Ed said...
I manage the search engines at a large corporation, and I can tell you that I get a LOT of negative feedback from folks complaining about the number of results that are returned.
The #1 complaint is often "Too many results! For example: 5,462 results for the word 'policy'?" How do you expect me to go through that many results?"
Mark Hurst said:
I never liked seeing how many results a search turned up. I don't want 3,000 results, I want ONE. MINE.
Brandie said...
"How do you know what (changed) query gives you the best result (the answer to the question you're looking for)?" - When you find the best result then you know.
Solutions:
scottmt said...
The only real way to search for a hard to find piece of information is to think of a phrase that would appear on the page and try it out.
JF said...
Regarding your desire to see that ONE result that best matches your request... I couldn't agree more... In order to get that ONE result that satisfies you, you have to know exactly what the best Google search is. You need to know the exact order, the exact tense of the combination of words you are looking for…
Comments:
Elisha said...
"…I don't want 3,000 results, i want ONE. MINE." - would be nice but it's unrealistic.
p8 said...
… BTW Has anyone ever looked passed the first 100 results?
My Sum Up:
There are users who complain that search engines give them too many results.
(See also my posting about my-hall-of-frustration )
There are users who desire one right result.
There are users who think it is possible to create one right result, others think it's unrealistic.
I think we have to mark this as a target and ask ourselves how to get there.
I'm sure that QT/Search is a step in the right direction. since it retrieves only few results in which the search words appear in every chunk.
I'll try in the future to build a version that will choose the best answer from QT/Search SERP and give the user only one answer.
In case there is no such answer it will notify the user about it– that will also be only one answer – NO.
Thursday, January 12, 2006
automatic music annotation
Since QT/search is limited to text I decided to explore ways to make it fit for searching music as well.
Here's a collection of excerpts on this subject:
http://mill.ucsd.edu/dturnbul/Papers/AutomaticMusicAnnotation2.ppt Automatic Music Annotation
A number of research systems have been developed that automatically annotate music. Automatic annotation uses low-level audio content to describe high-level musical concepts. The four works have been chosen based on their contribution to musical feature design. Although the features have been designed for classification by genre, they are useful for other annotation tasks (emotion, instrumentation, rhythmic structure)…Pachet and Cazaly (2003) review six genre classification systems that have been developed before 2002.
http://www.cs.ucsd.edu/~dturnbul/Papers/annotateMusic.pdf
In the last ten years, computer-based systems have been developed to automatically classify music according to a high-level musical concept such as genre or instrumentation. These automatic music annotation systems are useful for the storage and retrieval of music from a large database of musical content.
In general, a system begins by extracting features for each song. The labels and features for a set of labeled songs are used by a supervised learning algorithm to produce a classifier. This classifier can then be used to provide labels for unlabeled songs. In this paper, we examine commercial and academic approaches to musical annotation involving genre, instrumentation, rhythmic style, and emotion. We also describe various musical feature extraction techniques that have been developed for musical genre classification systems. Lastly, we suggest the use of latent variable models as an alternative to the supervised learning approach for music annotation.
When a listener scans the radio in search of an agreeable station, a decision about whether to settle or to keep searching is made based on a small clip of audio. Immediately the listener can determine if the radio station is broadcasting human speech, music, or silence. In the case of music, he or she can usually understand some notion of genre, instrumentation, and tempo. In some cases, the listener can identify the artist and title of the song if it is similar (or identical) to songs previously heard. The question is whether automatic methods can also be employed to deduce high-level information from audio content.
http://en.wikipedia.org/wiki/Query_by_humming Query by humming
Query by humming (QBH) is a music retrieval system that branches off the original classification systems of title, artist, composer, and genre.The system involves taking a user-hummed melody (input query) and comparing it to an existing database. The system then returns a ranked list of music closest to the input query.
http://querybyhum.cs.nyu.edu NYU Query by Humming
A Query by Humming system allows the user to find a song by humming part of the tune.The idea is simple: you hum into the microphone, the computer records the hum and extracts certain features corresponding to the melody and rhythm characteristics, and it then compares the features to the features of the songs in the database.
http://www.wired.com/news/digiwood/0,1412,57317,00.html Wired News: Song Search: A Real Humdinger
It's called "Query by Humming," a type of melody-recognition software program on display at this week's Midem music conference in Cannes that identifies a song by title and composer based on a person humming a few bars into a microphone.
http://querybyhum.cs.nyu.edu/index.php?p=about NYU Query by Humming
A Query by Humming system allows the user to find a song by humming part of the tune.The idea is simple: you hum into the microphone, the computer records the hum and extracts certain features corresponding to the melody and rhythm characteristics, and it then compares the features to the features of the songs in the database.
http://mitpress.mit.edu/catalog/item/default.asp?ttype=6&tid=14057 Computer Music Journal - The MUSART Testbed for Query-By-Humming ...
Online catalogs are already approaching one million songs, so it is important to study new techniques for searching these vast stores of audio. One approach to finding music that has received much attention is Query-by-Humming (QBH).This approach enables users to retrieve songs and information about them by singing, humming, or whistling a melodic fragment. In QBH systems, the query is a digital audio recording of the user, and the ultimate target is a complete digital audio recording.
http://portal.acm.org/citation.cfm?id=354520 A practical query-by-humming system for a large music database
A practical query-by-humming system for a large music database
The most significant improvement our system has over general query-by-humming systems is that all processing of musical information is done based on beats instead of notes. This type of query processing is robust against queries generated from erroneous input. In addition, acoustic information is transcribed and converted into relative intervals and is used for making feature vectors.
http://en.wikipedia.org/wiki/Music_information_retrieval Music information retrieval
Music information retrieval or MIR is the interdisciplinary science of retrieving information from music.
http://www.music-ir.org/research_home.html Music Information Retrieval Research Bibliography homepage
Research and development in Music Information Retrieval (MIR) is such a multi-disciplinary area that we have difficulty keeping track of the work being done in all the disciplines.With this "Music Information Retrieval Annotated Bibliography", we hope to enable the much needed communication across the disciplinary boundaries by providing a) bibliographic control of the MIR literature and b) an important mechanism for members of each discipline to comprehend the contributions of the other disciplines.With the tools provided here, we are able to uniformly represent the important scholarly papers found in the MIR fields. By promoting such communication, MIR will be in a better position to fully realize the benefits that a multi-disciplinary research and development community offers.
http://ismir2001.ismir.net International Symposium on Music Information Retrieval (MUSIC IR 2001)
Interest in music information retrieval (music IR) is exploding.This is not surprising: music IR has the potential for a wide variety of applications in the educational and academic domains as well as for entertainment. Yet, until now, there has been no established forum specifically for people studying music retrieval.
Here's a collection of excerpts on this subject:
http://mill.ucsd.edu/dturnbul/Papers/AutomaticMusicAnnotation2.ppt Automatic Music Annotation
A number of research systems have been developed that automatically annotate music. Automatic annotation uses low-level audio content to describe high-level musical concepts. The four works have been chosen based on their contribution to musical feature design. Although the features have been designed for classification by genre, they are useful for other annotation tasks (emotion, instrumentation, rhythmic structure)…Pachet and Cazaly (2003) review six genre classification systems that have been developed before 2002.
http://www.cs.ucsd.edu/~dturnbul/Papers/annotateMusic.pdf
In the last ten years, computer-based systems have been developed to automatically classify music according to a high-level musical concept such as genre or instrumentation. These automatic music annotation systems are useful for the storage and retrieval of music from a large database of musical content.
In general, a system begins by extracting features for each song. The labels and features for a set of labeled songs are used by a supervised learning algorithm to produce a classifier. This classifier can then be used to provide labels for unlabeled songs. In this paper, we examine commercial and academic approaches to musical annotation involving genre, instrumentation, rhythmic style, and emotion. We also describe various musical feature extraction techniques that have been developed for musical genre classification systems. Lastly, we suggest the use of latent variable models as an alternative to the supervised learning approach for music annotation.
When a listener scans the radio in search of an agreeable station, a decision about whether to settle or to keep searching is made based on a small clip of audio. Immediately the listener can determine if the radio station is broadcasting human speech, music, or silence. In the case of music, he or she can usually understand some notion of genre, instrumentation, and tempo. In some cases, the listener can identify the artist and title of the song if it is similar (or identical) to songs previously heard. The question is whether automatic methods can also be employed to deduce high-level information from audio content.
http://en.wikipedia.org/wiki/Query_by_humming Query by humming
Query by humming (QBH) is a music retrieval system that branches off the original classification systems of title, artist, composer, and genre.The system involves taking a user-hummed melody (input query) and comparing it to an existing database. The system then returns a ranked list of music closest to the input query.
http://querybyhum.cs.nyu.edu NYU Query by Humming
A Query by Humming system allows the user to find a song by humming part of the tune.The idea is simple: you hum into the microphone, the computer records the hum and extracts certain features corresponding to the melody and rhythm characteristics, and it then compares the features to the features of the songs in the database.
http://www.wired.com/news/digiwood/0,1412,57317,00.html Wired News: Song Search: A Real Humdinger
It's called "Query by Humming," a type of melody-recognition software program on display at this week's Midem music conference in Cannes that identifies a song by title and composer based on a person humming a few bars into a microphone.
http://querybyhum.cs.nyu.edu/index.php?p=about NYU Query by Humming
A Query by Humming system allows the user to find a song by humming part of the tune.The idea is simple: you hum into the microphone, the computer records the hum and extracts certain features corresponding to the melody and rhythm characteristics, and it then compares the features to the features of the songs in the database.
http://mitpress.mit.edu/catalog/item/default.asp?ttype=6&tid=14057 Computer Music Journal - The MUSART Testbed for Query-By-Humming ...
Online catalogs are already approaching one million songs, so it is important to study new techniques for searching these vast stores of audio. One approach to finding music that has received much attention is Query-by-Humming (QBH).This approach enables users to retrieve songs and information about them by singing, humming, or whistling a melodic fragment. In QBH systems, the query is a digital audio recording of the user, and the ultimate target is a complete digital audio recording.
http://portal.acm.org/citation.cfm?id=354520 A practical query-by-humming system for a large music database
A practical query-by-humming system for a large music database
The most significant improvement our system has over general query-by-humming systems is that all processing of musical information is done based on beats instead of notes. This type of query processing is robust against queries generated from erroneous input. In addition, acoustic information is transcribed and converted into relative intervals and is used for making feature vectors.
http://en.wikipedia.org/wiki/Music_information_retrieval Music information retrieval
Music information retrieval or MIR is the interdisciplinary science of retrieving information from music.
http://www.music-ir.org/research_home.html Music Information Retrieval Research Bibliography homepage
Research and development in Music Information Retrieval (MIR) is such a multi-disciplinary area that we have difficulty keeping track of the work being done in all the disciplines.With this "Music Information Retrieval Annotated Bibliography", we hope to enable the much needed communication across the disciplinary boundaries by providing a) bibliographic control of the MIR literature and b) an important mechanism for members of each discipline to comprehend the contributions of the other disciplines.With the tools provided here, we are able to uniformly represent the important scholarly papers found in the MIR fields. By promoting such communication, MIR will be in a better position to fully realize the benefits that a multi-disciplinary research and development community offers.
http://ismir2001.ismir.net International Symposium on Music Information Retrieval (MUSIC IR 2001)
Interest in music information retrieval (music IR) is exploding.This is not surprising: music IR has the potential for a wide variety of applications in the educational and academic domains as well as for entertainment. Yet, until now, there has been no established forum specifically for people studying music retrieval.
Wednesday, January 11, 2006
Automatic Video Annotation
Right now QT/search is working only with text , but it is worth exploring whether it can work also with multimedia. In order to learn how to use QT/search for searching video I collected the following information: (This is a sequence article to "automatic image annotation")
http://news.com.com/Yahoo+tests+video+search+engine/2100-1025_3-5492779.html
Yahoo tests video search engine | CNET News.com
o Yahoo has unveiled a video search engine to the serve the growing appetite for multimedia entertainment online.
o The proposed system builds on a standard for syndicating content to other Web sites by allowing publishers to add text, or metatags, to their media files. That way, the RSS feeds can be sent to Yahoo for indexing in the search engine. Eventually, Yahoo said, the system could be used to let people aggregate video feeds on a personalized Web page, for example.
http://www.ysearchblog.com/archives/000060.html
Yahoo! Search Blog: Yahoo! Video Search Beta
Nice, but how come an "early beta" of Yahoo Video produces exactly the same results as the established Altavista Video Search? Apart from the obvious Yahoo-Overture-Altavista ownership chain, I mean. Did you merge the Altavista engine with Yahoo's or vice versa?
html">http://www.w3.org/People/howcome/p/telektronikk-4-93/Davis_M.html
Media streams: an iconic visual language for video annotation
The central problem in the creation of robust and extensible systems for manipulating video information lies in representing and visualizing video content. Currently, content providers possess large archives of film and video for which they lack sufficient tools for search and retrieval. For the types of applications that will be developed in the near future (interactive television, personalized news, video on demand, etc. ) these archives will remain a largely untapped resource, unless we are able to access their contents. Without a way of accessing video information in terms of its content, a thousand hours of video is less useful than one. With one hour of video, its content can be stored in human memory, but as we move up in orders of magnitude, we need to find ways of creating machine-readable and human-usable representations of video content. It is not simply a matter of cataloguing reels or tapes, but of representing and manipulating the content of video at multiple levels of granularity and with greater descriptive richness. This paper attempts to address that challenge.
http://portal.acm.org/citation.cfm?id=1101826.1101844
Semi-automatic video annotation based on active learning with . . .
Semi-automatic video annotation based on active learning with multiple complementary predictors
In this paper, we will propose a novel semi-automatic annotation scheme for video semantic classification. It is well known that the large gap between high-level semantics and low-level features is difficult to be bridged by full-automatic content analysis mechanisms. To narrow down this gap, relevance feedback has been introduced in a number of literatures, especially in those works addressing the problem of image retrieval. And at the same time, active learning is also suggested to accelerate the converging speed of the learning process by labeling the most informative samples.
http://portal.acm.org/citation.cfm?id=1101149.1101235
Automatic video annotation using ontologies extended with visual . . .
Automatic video annotation using Ontologies extended with visual information
Classifying video elements according to some pre-defined ontology of the video content domain is a typical way to perform video annotation. Ontologies are defined by establishing relationships between linguistic terms that specify domain concepts at different abstraction levels. However, although linguistic terms are appropriate to distinguish event and object categories, they are inadequate when they must describe specific patterns of events or video entities. Instead, in these cases, pattern specifications can be better expressed through visual prototypes that capture the essence of the event or entity. Therefore pictorially enriched ontologies, that include both visual and linguistic concepts, can be useful to support video annotation up to the level of detail of pattern specification.
Annotation is performed associating occurrences of events, or entities, to higher level concepts by checking their proximity to visual concepts that are hierarchically linked to higher level semantics.
http://vismod.media.mit.edu/vismod/demos/football/annotation.htm
Computers Watching Football - Video Annotation
The NFL has recently converted to using all digital media so that the video can be accessed and viewed directly from a computer.
Video annotation is the task of generating such descriptions. It is different than conventional computer vision image understanding in that one is primarily interested in what is happening in a scene, as opposed to what is in the scene. The goal is to describe the behavior or action that takes place in a manner relevant to the domain.
In the "football domain," we would like to build a computer system that will automatically annotate video automatically or provide a semi-automatic process for the VAC.
Video annotation is a problem that will become much more important in the next few years as video databases begin to grow and methods must be developed for automatic database summary, analysis, and retrieval. Other annotation problems being studied in the Vision and Modeling Group of the MIT Media Lab include dance steps and human gesture .
We have chosen to study the automatic annotation of football plays for four reasons: (1) football has a known descriptive language, (2), football has a rich set of domain rules and domain expectations, (3), football annotation is a real-world problem, and (4) it's fun.
An automatic football annotation system must have some input data upon which to make a preliminary play hypothesis. In the football annotation problem, we are using player trajectories. In the first stage of our annotation project, we have implemented a computer vision football-player tracker that uses contextual knowledge to track football players as they move around a field.
http://domino.watson.ibm.com/library/CyberDig.nsf/a3807c5b4823c53f85256561006324be/b4d1f3b9a6c594ea852565b6006bf7b7?
OpenDocument IBM Research | Technical Paper Search | Automatic Text Extraction From Video For Content-Based Annotation and ...
Efficient content-based retrieval of image and video databases is an important emerging application due to rapid proliferation of image and digital video data on the Internet and corporate intranets and exponential growth of video content in general. Text either embedded or superimposed within video frames is very useful for describing the semantic content of the frames, as it enables both keyword and free-text based search, automatic video logging, and video cataloging. Extracting text directly from video data becomes especially important when closed captioning or speech recognition is not available to generate textual transcripts of audio or when video footage that completely lacks audio needs to be automatically annotated and searched based on frame content. Towards building a video query system, we have developed a scheme for automatically extracting text from digital images and videos for content annotation and retrieval.
http://news.com.com/Yahoo+tests+video+search+engine/2100-1025_3-5492779.html
Yahoo tests video search engine | CNET News.com
o Yahoo has unveiled a video search engine to the serve the growing appetite for multimedia entertainment online.
o The proposed system builds on a standard for syndicating content to other Web sites by allowing publishers to add text, or metatags, to their media files. That way, the RSS feeds can be sent to Yahoo for indexing in the search engine. Eventually, Yahoo said, the system could be used to let people aggregate video feeds on a personalized Web page, for example.
http://www.ysearchblog.com/archives/000060.html
Yahoo! Search Blog: Yahoo! Video Search Beta
Nice, but how come an "early beta" of Yahoo Video produces exactly the same results as the established Altavista Video Search? Apart from the obvious Yahoo-Overture-Altavista ownership chain, I mean. Did you merge the Altavista engine with Yahoo's or vice versa?
html">http://www.w3.org/People/howcome/p/telektronikk-4-93/Davis_M.html
Media streams: an iconic visual language for video annotation
The central problem in the creation of robust and extensible systems for manipulating video information lies in representing and visualizing video content. Currently, content providers possess large archives of film and video for which they lack sufficient tools for search and retrieval. For the types of applications that will be developed in the near future (interactive television, personalized news, video on demand, etc. ) these archives will remain a largely untapped resource, unless we are able to access their contents. Without a way of accessing video information in terms of its content, a thousand hours of video is less useful than one. With one hour of video, its content can be stored in human memory, but as we move up in orders of magnitude, we need to find ways of creating machine-readable and human-usable representations of video content. It is not simply a matter of cataloguing reels or tapes, but of representing and manipulating the content of video at multiple levels of granularity and with greater descriptive richness. This paper attempts to address that challenge.
http://portal.acm.org/citation.cfm?id=1101826.1101844
Semi-automatic video annotation based on active learning with . . .
Semi-automatic video annotation based on active learning with multiple complementary predictors
In this paper, we will propose a novel semi-automatic annotation scheme for video semantic classification. It is well known that the large gap between high-level semantics and low-level features is difficult to be bridged by full-automatic content analysis mechanisms. To narrow down this gap, relevance feedback has been introduced in a number of literatures, especially in those works addressing the problem of image retrieval. And at the same time, active learning is also suggested to accelerate the converging speed of the learning process by labeling the most informative samples.
http://portal.acm.org/citation.cfm?id=1101149.1101235
Automatic video annotation using ontologies extended with visual . . .
Automatic video annotation using Ontologies extended with visual information
Classifying video elements according to some pre-defined ontology of the video content domain is a typical way to perform video annotation. Ontologies are defined by establishing relationships between linguistic terms that specify domain concepts at different abstraction levels. However, although linguistic terms are appropriate to distinguish event and object categories, they are inadequate when they must describe specific patterns of events or video entities. Instead, in these cases, pattern specifications can be better expressed through visual prototypes that capture the essence of the event or entity. Therefore pictorially enriched ontologies, that include both visual and linguistic concepts, can be useful to support video annotation up to the level of detail of pattern specification.
Annotation is performed associating occurrences of events, or entities, to higher level concepts by checking their proximity to visual concepts that are hierarchically linked to higher level semantics.
http://vismod.media.mit.edu/vismod/demos/football/annotation.htm
Computers Watching Football - Video Annotation
The NFL has recently converted to using all digital media so that the video can be accessed and viewed directly from a computer.
Video annotation is the task of generating such descriptions. It is different than conventional computer vision image understanding in that one is primarily interested in what is happening in a scene, as opposed to what is in the scene. The goal is to describe the behavior or action that takes place in a manner relevant to the domain.
In the "football domain," we would like to build a computer system that will automatically annotate video automatically or provide a semi-automatic process for the VAC.
Video annotation is a problem that will become much more important in the next few years as video databases begin to grow and methods must be developed for automatic database summary, analysis, and retrieval. Other annotation problems being studied in the Vision and Modeling Group of the MIT Media Lab include dance steps and human gesture .
We have chosen to study the automatic annotation of football plays for four reasons: (1) football has a known descriptive language, (2), football has a rich set of domain rules and domain expectations, (3), football annotation is a real-world problem, and (4) it's fun.
An automatic football annotation system must have some input data upon which to make a preliminary play hypothesis. In the football annotation problem, we are using player trajectories. In the first stage of our annotation project, we have implemented a computer vision football-player tracker that uses contextual knowledge to track football players as they move around a field.
http://domino.watson.ibm.com/library/CyberDig.nsf/a3807c5b4823c53f85256561006324be/b4d1f3b9a6c594ea852565b6006bf7b7?
OpenDocument IBM Research | Technical Paper Search | Automatic Text Extraction From Video For Content-Based Annotation and ...
Efficient content-based retrieval of image and video databases is an important emerging application due to rapid proliferation of image and digital video data on the Internet and corporate intranets and exponential growth of video content in general. Text either embedded or superimposed within video frames is very useful for describing the semantic content of the frames, as it enables both keyword and free-text based search, automatic video logging, and video cataloging. Extracting text directly from video data becomes especially important when closed captioning or speech recognition is not available to generate textual transcripts of audio or when video footage that completely lacks audio needs to be automatically annotated and searched based on frame content. Towards building a video query system, we have developed a scheme for automatically extracting text from digital images and videos for content annotation and retrieval.
Tuesday, January 10, 2006
Automatic image annotation
QT/search is text only research tool. In order to learn how to use it for searching images I collected the following information:
http://research. microsoft. com/users/marycz/semi-auto-annotatoin--full. pdf
Labeling the semantic content of images (or generally, multimedia objects) with a set of keywords is a problem known as image (or multimedia) annotation. Annotation is used primarily for image database management, especially for image retrieval. Annotated images can usually be found using keyword-based search, while non-annotated images can be extremely difficult to find in large databases. Since the use of image-based analysis techniques (what is often called content-based image retrieval) (Flickner et al. , 1995) is still not very accurate or robust, keyword-based image search is preferable and image annotation is therefore unavoidable. In addition, qualitative research by Rodden (1999) suggests that users are likely to find searching for photos based on the text of their annotations as a more useful and likely route in future, computer-aided image databases.
2.http://amazon. ece. utexas. edu/~qasim/research. htm CIRES: Content based Image REtrieval System
CIRES is a robust content-based image retrieval system based upon a combination of higher-level and lower-level vision principles. Higher-level analysis uses perceptual organization, inference and grouping principles to extract semantic information describing the structural content of an image. Lower-level analysis employs a channel energy model to describe image texture, and utilizes color histogram techniques.
3.http://en. wikipedia. org/wiki/CBIR Content-based image retrieval - Wikipedia, the free encyclopedia
Content-based image retrieval (CBIR), also known as query by image content (QBIC) and content-based visual information retrieval (CBVIR) is the application of computer vision to the image retrieval problem, that is, the problem of searching for digital images in large databases. "Content-based" means that the search makes use of the contents of the images themselves, rather than relying on human-inputted metadata such as captions or keywords. A content-based image retrieval system (CBIRS) is a piece of software that implements CBIR.
There is one problematic issue with the use of the term "Content Based Image Retrieval". The way the term CBIR is generally used, refers only to the structural content of images. This use excludes image retrieval based on textual annotation.
Cortina - Content Based Image Retrieval for 3 Million Images.
Octagon - Free Java based Content-Based Image Retrieval software.
4. http://www. cs. washington. edu/research/imagedatabase Object and Concept Recognition for Content-Based Image Retrieval
These search engines can retrieve images by keywords or by image content such as color, texture, and simple shape properties. Content-based image retrieval is not yet a commercial success, because most real users searching for images want to specify the semantic class of the scene or the object(s) it should contain. The large commercial image providers are still using human indexers to select keywords for their images, even though their databases contain thousands or, in some cases, millions of images. Automatic object recognition is needed, but most successful computer vision object recognition systems can only handle particular objects, such as industrial parts, that can be represented by precise geometric models.
5.http://en. wikipedia. org/wiki/Automatic_image_annotation
Automatic image annotation is the process by which a computer system automatically assigns metadata in the form of captioning or keywords to a digital image. This application of computer vision techniques is used in image retrieval systems to organize and locate images of interest from a database.
This method can be regarded as a type of multi-class image classification with a very large number of classes - as large as the vocabulary size. Typically, image analysis in the form of extracted feature vectors and the training annotation words are used by machine learning techniques to attempt to automatically apply annotations to new images. The first methods learned the correlations between image features and training annotations, then techniques were developed using machine translation to try and translate the textual vocabulary with the 'visual vocabulary', or clustered regions known as blobs. Work following these efforts have included classification approaches, relevance models and so on.
The advantages of automatic image annotation versus content-based image retrieval are that queries can be more naturally specified by the user [1]. CBIR generally (at present) requires users to search by image concepts such as color and texture, or finding example queries. Certain image features in example images may override the concept that the user is really focusing on. The traditional methods of image retrieval such as those used by libraries have relied on manually annotated images, which is expensive and time-consuming, especially given the large and constantly-growing image databases in existence.
6. http://portal. acm. org/citation. cfm?id=860459 Automatic image annotation and retrieval using cross-media . . .
Libraries have traditionally used manual image annotation for indexing and then later retrieving their image collections. However, manual image annotation is an expensive and labor intensive procedure and hence there has been great interest in coming up with automatic ways to retrieve images based on content. Here, we propose an automatic approach to annotating and retrieving images based on a training set of images. We assume that regions in an image can be described using a small vocabulary of blobs. Blobs are generated from image features using clustering. Given a training set of images with annotations, we show that probabilistic models allow us to predict the probability of generating a word given the blobs in an image. This may be used to automatically annotate and retrieve images given a word as a query. We show that relevance models allow us to derive these probabilities in a natural way.
7.http://portal. acm. org/citation. cfm?id=1008992. 1009055 Automatic image annotation by using concept-sensitive salient . . .
Multi-level annotation of images is a promising solution to enable more effective semantic image retrieval by using various keywords at different semantic levels. In this paper, we propose a multi-level approach to annotate the semantics of natural scenes by using both the dominant image components and the relevant semantic concepts. In contrast to the well-known image-based and region-based approaches, we use the salient objects as the dominant image components to achieve automatic image annotation at the content level.
8. http://en. wikipedia. org/wiki/Image_retrieval Image retrieval
An image retrieval system is a computer system for browsing, searching and retrieving images from a large database of digital images. Most traditional and common methods of image retrieval utilize some method of adding metadata such as captioning, keywords, or descriptions to the images so that retrieval can be performed over the annotation words. Manual image annotation is time-consuming, laborious and expensive; to address this, there has been a large amount of research done on automatic image annotation. Additionally, the increase in social web applications and the semantic web have inspired the development of several web-based image annotation tools.
9.http://citeseer. ist. psu. edu/419422. html
A novel approach to semi-automatically and progressively annotating images with keywords is presented. The progressive annotation process is embedded in the course of integrated keyword-based and content-based image retrieval and user feedback. When the user submits a keyword query and then provides relevance feedback, the search keywords are automatically added to the images that receive positive feedback and can then facilitate keyword-based image retrieval in the future.
10.http://en. wikipedia. org/wiki/Computer_graphics
Blobs: a technique for representing surfaces without specifying a hard boundary representation, usually implemented as a procedural surface like a Van der Waals equipotential (in chemistry).
11.http://runevision. com/3d/blobs
The blob primitive in POV-Ray is a very flexible shape, that can for example be used to create organic-looking shapes. At first it can be a little difficult to understand how blobs work, because the shape of the blob is affected by several variables. The most important variables are the threshold of the blob, the strength of each component, and the radius of each component.
http://research. microsoft. com/users/marycz/semi-auto-annotatoin--full. pdf
Labeling the semantic content of images (or generally, multimedia objects) with a set of keywords is a problem known as image (or multimedia) annotation. Annotation is used primarily for image database management, especially for image retrieval. Annotated images can usually be found using keyword-based search, while non-annotated images can be extremely difficult to find in large databases. Since the use of image-based analysis techniques (what is often called content-based image retrieval) (Flickner et al. , 1995) is still not very accurate or robust, keyword-based image search is preferable and image annotation is therefore unavoidable. In addition, qualitative research by Rodden (1999) suggests that users are likely to find searching for photos based on the text of their annotations as a more useful and likely route in future, computer-aided image databases.
2.http://amazon. ece. utexas. edu/~qasim/research. htm CIRES: Content based Image REtrieval System
CIRES is a robust content-based image retrieval system based upon a combination of higher-level and lower-level vision principles. Higher-level analysis uses perceptual organization, inference and grouping principles to extract semantic information describing the structural content of an image. Lower-level analysis employs a channel energy model to describe image texture, and utilizes color histogram techniques.
3.http://en. wikipedia. org/wiki/CBIR Content-based image retrieval - Wikipedia, the free encyclopedia
Content-based image retrieval (CBIR), also known as query by image content (QBIC) and content-based visual information retrieval (CBVIR) is the application of computer vision to the image retrieval problem, that is, the problem of searching for digital images in large databases. "Content-based" means that the search makes use of the contents of the images themselves, rather than relying on human-inputted metadata such as captions or keywords. A content-based image retrieval system (CBIRS) is a piece of software that implements CBIR.
There is one problematic issue with the use of the term "Content Based Image Retrieval". The way the term CBIR is generally used, refers only to the structural content of images. This use excludes image retrieval based on textual annotation.
Cortina - Content Based Image Retrieval for 3 Million Images.
Octagon - Free Java based Content-Based Image Retrieval software.
4. http://www. cs. washington. edu/research/imagedatabase Object and Concept Recognition for Content-Based Image Retrieval
These search engines can retrieve images by keywords or by image content such as color, texture, and simple shape properties. Content-based image retrieval is not yet a commercial success, because most real users searching for images want to specify the semantic class of the scene or the object(s) it should contain. The large commercial image providers are still using human indexers to select keywords for their images, even though their databases contain thousands or, in some cases, millions of images. Automatic object recognition is needed, but most successful computer vision object recognition systems can only handle particular objects, such as industrial parts, that can be represented by precise geometric models.
5.http://en. wikipedia. org/wiki/Automatic_image_annotation
Automatic image annotation is the process by which a computer system automatically assigns metadata in the form of captioning or keywords to a digital image. This application of computer vision techniques is used in image retrieval systems to organize and locate images of interest from a database.
This method can be regarded as a type of multi-class image classification with a very large number of classes - as large as the vocabulary size. Typically, image analysis in the form of extracted feature vectors and the training annotation words are used by machine learning techniques to attempt to automatically apply annotations to new images. The first methods learned the correlations between image features and training annotations, then techniques were developed using machine translation to try and translate the textual vocabulary with the 'visual vocabulary', or clustered regions known as blobs. Work following these efforts have included classification approaches, relevance models and so on.
The advantages of automatic image annotation versus content-based image retrieval are that queries can be more naturally specified by the user [1]. CBIR generally (at present) requires users to search by image concepts such as color and texture, or finding example queries. Certain image features in example images may override the concept that the user is really focusing on. The traditional methods of image retrieval such as those used by libraries have relied on manually annotated images, which is expensive and time-consuming, especially given the large and constantly-growing image databases in existence.
6. http://portal. acm. org/citation. cfm?id=860459 Automatic image annotation and retrieval using cross-media . . .
Libraries have traditionally used manual image annotation for indexing and then later retrieving their image collections. However, manual image annotation is an expensive and labor intensive procedure and hence there has been great interest in coming up with automatic ways to retrieve images based on content. Here, we propose an automatic approach to annotating and retrieving images based on a training set of images. We assume that regions in an image can be described using a small vocabulary of blobs. Blobs are generated from image features using clustering. Given a training set of images with annotations, we show that probabilistic models allow us to predict the probability of generating a word given the blobs in an image. This may be used to automatically annotate and retrieve images given a word as a query. We show that relevance models allow us to derive these probabilities in a natural way.
7.http://portal. acm. org/citation. cfm?id=1008992. 1009055 Automatic image annotation by using concept-sensitive salient . . .
Multi-level annotation of images is a promising solution to enable more effective semantic image retrieval by using various keywords at different semantic levels. In this paper, we propose a multi-level approach to annotate the semantics of natural scenes by using both the dominant image components and the relevant semantic concepts. In contrast to the well-known image-based and region-based approaches, we use the salient objects as the dominant image components to achieve automatic image annotation at the content level.
8. http://en. wikipedia. org/wiki/Image_retrieval Image retrieval
An image retrieval system is a computer system for browsing, searching and retrieving images from a large database of digital images. Most traditional and common methods of image retrieval utilize some method of adding metadata such as captioning, keywords, or descriptions to the images so that retrieval can be performed over the annotation words. Manual image annotation is time-consuming, laborious and expensive; to address this, there has been a large amount of research done on automatic image annotation. Additionally, the increase in social web applications and the semantic web have inspired the development of several web-based image annotation tools.
9.http://citeseer. ist. psu. edu/419422. html
A novel approach to semi-automatically and progressively annotating images with keywords is presented. The progressive annotation process is embedded in the course of integrated keyword-based and content-based image retrieval and user feedback. When the user submits a keyword query and then provides relevance feedback, the search keywords are automatically added to the images that receive positive feedback and can then facilitate keyword-based image retrieval in the future.
10.http://en. wikipedia. org/wiki/Computer_graphics
Blobs: a technique for representing surfaces without specifying a hard boundary representation, usually implemented as a procedural surface like a Van der Waals equipotential (in chemistry).
11.http://runevision. com/3d/blobs
The blob primitive in POV-Ray is a very flexible shape, that can for example be used to create organic-looking shapes. At first it can be a little difficult to understand how blobs work, because the shape of the blob is affected by several variables. The most important variables are the threshold of the blob, the strength of each component, and the radius of each component.
Monday, January 09, 2006
Microcontent Comments
I already mentioned in the past that sometimes I need to retrieve a comment and I don't find it.
As a solution I collected comments that deal with a certain subject on one Blog page and showed my comments on the subject of Wikipedia.
This time I'll show comments on the subject of microcontent.
Table of contents for this posting:
1. Defining Microcontent
2. Authority Problem
3. The Future of Microcontent
4. Microcontent Revolution
5. Microcontent Manipulations
6. New Kind of Microcontent
7. Shift in Concept
Defining Microcontent
http://novaspivack.typepad.com/nova_spivacks_weblog/2003/12/defining_microc.html
Nova Spivack wrote about "Defining Microcontent"
Comment:
Long ago, while I was learning folk tales at the University, I came across the
Aarne-Thompson Index of "Motifs".
A motif may be an action, an item, a character, or even a direct quote from the
book. However, whatever that motif is, Aarne and Thompson have identified it as
an improtant characteristic of at least one folk tale. Their method involves
comparing the motifs present in the stories. Stories that have many of the same
motifs are then classified as related and given a number.
This idea of taking the smallest unit of an idea fascinated me ever since and the result is QTSaver, which arranges the same web motifs according to different needs.
http://phaidon.philo.at/martin/archives/000404.html
Martin wrote:
it seems I simply was one of the first ever trying to find a definition, back then, six very long months ago, before "web 2.0" exploded… I'm a humanities man, interested in the new kind of semantic web emerging from microcontent-set-free…
Comment:
Here's a tip for your new definition:
Web 2.0 is Peer Production
See more on
http://qtsaver.blogspot.com/2005/12/peer-production.html
Martin wrote:
(This is apparently not spam)
QTsaver is a beta that:
"If there is an article on Wikipedia about "Siamese cat" - since Wikipedia doesn't update content related to "Siamese cat" – I'll write an article about the same subject which will have regularly updated content, powered by QTSaver search. A friend who heard about my plan commented that it is somewhat like peer production but using software (QTSaver) in the place of humans to create content."
Authority Problem
http://gondwanaland.com/mlog/2005/12/24/anti-authoritarian-age/
Mike Linksvayer wrote about " The Anti-Authoritarian Age":
People crave authority, and any system that doesn’t claim authority is suspect.
The most extreme example does not involve the web, blogs, wikipedia, markets, or democracy... Science is the extreme example, and its dual, religion.
Comment:
This authority problem will get worse in the near future since Web 2.0 is about microcontents that are torn from the original article - so that the author is forgotten at
the end of the day. It looks like you appreciate encyclopedias a little too much. IMO they are old macro content monsters that have to be shattered to atoms of knowledge and rearranged according to users needs.
http://helenwang.rdvp.org/blog/2005/02/future-of-microcontent.html
Helen Wang wrote about the future of microcontent:
2 billion mobile subscribers worldwide in 2005
600 handsets are sold every year, and 2/3 of them are camera phones.
20 million digital cameras
7.7 billion digital impages were printed
82 billion SMS were sent in 2004
50 million MP3 players
So, what are the implications of these numbers? I guess some people smell the money, others see this as a new opportunity.
Comment:
The future of microcontent is that humanity will have to translate billions of macro content web pages into microcontent web pages,because macro content is not efficient enough for human needs – it gives us more than we need. What we need is a certain amount of words that answer our curious queries – not more, not less.
Microcontent Revolution
http://communities-dominate.blogs.com/brands/2005/11/storming_the_ba.html
Alan Moore writes about "Storming the Bastille":
We are entering a world where content will be increasingly delivered through internet and internet-mobile-protocol-based networks that are non-linear, on-demand and entirely self-scheduled. In that world, the viewer – not the broadcaster – whoever that may be, will decide what is consumed, when, and how.
Comment:
You can have another angle on the above revolution on
http://qtsaver.blogspot.com/2005/11/micro-content-revolution.html
microcontent manipulations
http://www.josschuurmans.com/josschuurmans/2005/11/does_anybody_kn.html
Jos Schuurmans asked on his Blog:
"Does anybody know of an effort to standardize Q&A Blog entry types to serve natural question search?"
Comment:
IMO You can learn a lot about the new field that you opened here for research from the Wondir model of questions and answers
(http://wondiring.typepad.com/) and from the microcontent manipulations of http://qtsaver..com/
New Kind Of Microcontent
http://blog.broadbandmechanics.com/2005/11/syndicate-2
Marc’s Voice:
We will be using this year’s conference as a launching pad for Structured Blogging.org V2 and I’ll be doing a panel on Compound Feeds, Microcontent and the Future of Syndication.
Comment:
Here is a new kind of microcontent that might interest you
http://qtsaver.dynalias.com/
Shift In Concept
http://64.233.183.104/search?q=cache:nTvELWrMOX8J:www.diaryofawebsite.co.uk/viewentry.php%3Fid%3D20+zeevveez+micro&hl=iw…This sees Web 2.0 as a version where information is dissolved into "micro-content". So, take a little dash of application, a handful of RSS and dilute with social networking - bring to the boil and reduce over the heat of a desktop environment; this is the recipe for Web 2.0.
Comment:
Web 2.0 is not a recipe and is not about external design - it is a shift in concept: The current sequence of articles from a certain beginning to a certain end will be shattered to pieces and the development of an argument from assumption to deduction will lose its hypnotic power. Each excerpt will have a life of its own in web 2.0 and will find its place sometimes in one role other times in another role. The original intention of the author will be forgotten and each new author will recycle the excerpt for his new intention.
Mobile Internet Access
http://www.456bereastreet.com/archive/200511/the_freedom_of_mobile_internet_access/
Roger Johansson wrote about "The freedom of mobile Internet access"
Comment:
There are today 4 ways to mobile surf the Web:
Through cache databases for race scores, weather, horoscopes, etc. it is not really "mobile surfing of the Web" because surfing is only on the cache, which is a pre arranged process of structuring the raw web and caging it in rows and columns.
Through mobile surf - few people use this option because sites don't fit mobiles; there are too long or too short answers for their queries; Images are too big.
Through I-mode - Works only on few thousand special sites and doesn't touch the vast info that populates the Web. I-mode has 43 million customers in Japan, and over 3 million in the rest of the world.
Through http://qtsaver.com/ which is the first real mobile surf of the Web!!! It gets into the vital Web microcontents text (not multimedia) that fit the mobile screen perfectly.
P.S
Web 2.0 is about multiplying and remixing microcontents.
Comments are considered microcontents since they are usually short and since they tend to deal with only one theme.
Web 2.0 characteristic features are cutting and pasting and then rearranging.
IMHO what I did in order to compose this posting is a typical Web 2.0 technique – I searched the comments, found them, cut them from their context, omitted their design, pasted them in a new format and shared the results with my community.
As a solution I collected comments that deal with a certain subject on one Blog page and showed my comments on the subject of Wikipedia.
This time I'll show comments on the subject of microcontent.
Table of contents for this posting:
1. Defining Microcontent
2. Authority Problem
3. The Future of Microcontent
4. Microcontent Revolution
5. Microcontent Manipulations
6. New Kind of Microcontent
7. Shift in Concept
Defining Microcontent
http://novaspivack.typepad.com/nova_spivacks_weblog/2003/12/defining_microc.html
Nova Spivack wrote about "Defining Microcontent"
Comment:
Long ago, while I was learning folk tales at the University, I came across the
Aarne-Thompson Index of "Motifs".
A motif may be an action, an item, a character, or even a direct quote from the
book. However, whatever that motif is, Aarne and Thompson have identified it as
an improtant characteristic of at least one folk tale. Their method involves
comparing the motifs present in the stories. Stories that have many of the same
motifs are then classified as related and given a number.
This idea of taking the smallest unit of an idea fascinated me ever since and the result is QTSaver, which arranges the same web motifs according to different needs.
http://phaidon.philo.at/martin/archives/000404.html
Martin wrote:
it seems I simply was one of the first ever trying to find a definition, back then, six very long months ago, before "web 2.0" exploded… I'm a humanities man, interested in the new kind of semantic web emerging from microcontent-set-free…
Comment:
Here's a tip for your new definition:
Web 2.0 is Peer Production
See more on
http://qtsaver.blogspot.com/2005/12/peer-production.html
Martin wrote:
(This is apparently not spam)
QTsaver is a beta that:
"If there is an article on Wikipedia about "Siamese cat" - since Wikipedia doesn't update content related to "Siamese cat" – I'll write an article about the same subject which will have regularly updated content, powered by QTSaver search. A friend who heard about my plan commented that it is somewhat like peer production but using software (QTSaver) in the place of humans to create content."
Authority Problem
http://gondwanaland.com/mlog/2005/12/24/anti-authoritarian-age/
Mike Linksvayer wrote about " The Anti-Authoritarian Age":
People crave authority, and any system that doesn’t claim authority is suspect.
The most extreme example does not involve the web, blogs, wikipedia, markets, or democracy... Science is the extreme example, and its dual, religion.
Comment:
This authority problem will get worse in the near future since Web 2.0 is about microcontents that are torn from the original article - so that the author is forgotten at
the end of the day. It looks like you appreciate encyclopedias a little too much. IMO they are old macro content monsters that have to be shattered to atoms of knowledge and rearranged according to users needs.
http://helenwang.rdvp.org/blog/2005/02/future-of-microcontent.html
Helen Wang wrote about the future of microcontent:
2 billion mobile subscribers worldwide in 2005
600 handsets are sold every year, and 2/3 of them are camera phones.
20 million digital cameras
7.7 billion digital impages were printed
82 billion SMS were sent in 2004
50 million MP3 players
So, what are the implications of these numbers? I guess some people smell the money, others see this as a new opportunity.
Comment:
The future of microcontent is that humanity will have to translate billions of macro content web pages into microcontent web pages,because macro content is not efficient enough for human needs – it gives us more than we need. What we need is a certain amount of words that answer our curious queries – not more, not less.
Microcontent Revolution
http://communities-dominate.blogs.com/brands/2005/11/storming_the_ba.html
Alan Moore writes about "Storming the Bastille":
We are entering a world where content will be increasingly delivered through internet and internet-mobile-protocol-based networks that are non-linear, on-demand and entirely self-scheduled. In that world, the viewer – not the broadcaster – whoever that may be, will decide what is consumed, when, and how.
Comment:
You can have another angle on the above revolution on
http://qtsaver.blogspot.com/2005/11/micro-content-revolution.html
microcontent manipulations
http://www.josschuurmans.com/josschuurmans/2005/11/does_anybody_kn.html
Jos Schuurmans asked on his Blog:
"Does anybody know of an effort to standardize Q&A Blog entry types to serve natural question search?"
Comment:
IMO You can learn a lot about the new field that you opened here for research from the Wondir model of questions and answers
(http://wondiring.typepad.com/) and from the microcontent manipulations of http://qtsaver..com/
New Kind Of Microcontent
http://blog.broadbandmechanics.com/2005/11/syndicate-2
Marc’s Voice:
We will be using this year’s conference as a launching pad for Structured Blogging.org V2 and I’ll be doing a panel on Compound Feeds, Microcontent and the Future of Syndication.
Comment:
Here is a new kind of microcontent that might interest you
http://qtsaver.dynalias.com/
Shift In Concept
http://64.233.183.104/search?q=cache:nTvELWrMOX8J:www.diaryofawebsite.co.uk/viewentry.php%3Fid%3D20+zeevveez+micro&hl=iw…This sees Web 2.0 as a version where information is dissolved into "micro-content". So, take a little dash of application, a handful of RSS and dilute with social networking - bring to the boil and reduce over the heat of a desktop environment; this is the recipe for Web 2.0.
Comment:
Web 2.0 is not a recipe and is not about external design - it is a shift in concept: The current sequence of articles from a certain beginning to a certain end will be shattered to pieces and the development of an argument from assumption to deduction will lose its hypnotic power. Each excerpt will have a life of its own in web 2.0 and will find its place sometimes in one role other times in another role. The original intention of the author will be forgotten and each new author will recycle the excerpt for his new intention.
Mobile Internet Access
http://www.456bereastreet.com/archive/200511/the_freedom_of_mobile_internet_access/
Roger Johansson wrote about "The freedom of mobile Internet access"
Comment:
There are today 4 ways to mobile surf the Web:
Through cache databases for race scores, weather, horoscopes, etc. it is not really "mobile surfing of the Web" because surfing is only on the cache, which is a pre arranged process of structuring the raw web and caging it in rows and columns.
Through mobile surf - few people use this option because sites don't fit mobiles; there are too long or too short answers for their queries; Images are too big.
Through I-mode - Works only on few thousand special sites and doesn't touch the vast info that populates the Web. I-mode has 43 million customers in Japan, and over 3 million in the rest of the world.
Through http://qtsaver.com/ which is the first real mobile surf of the Web!!! It gets into the vital Web microcontents text (not multimedia) that fit the mobile screen perfectly.
P.S
Web 2.0 is about multiplying and remixing microcontents.
Comments are considered microcontents since they are usually short and since they tend to deal with only one theme.
Web 2.0 characteristic features are cutting and pasting and then rearranging.
IMHO what I did in order to compose this posting is a typical Web 2.0 technique – I searched the comments, found them, cut them from their context, omitted their design, pasted them in a new format and shared the results with my community.
Subscribe to:
Posts (Atom)